Категории:
ДомЗдоровьеЗоологияИнформатикаИскусствоИскусствоКомпьютерыКулинарияМаркетингМатематикаМедицинаМенеджментОбразованиеПедагогикаПитомцыПрограммированиеПроизводствоПромышленностьПсихологияРазноеРелигияСоциологияСпортСтатистикаТранспортФизикаФилософияФинансыХимияХоббиЭкологияЭкономикаЭлектроника
Двухуровневые схемы предсказания переходов
Рассмотренные одноуровневые схемы предсказаний ориентированы на те команды УП, очередной исход которых существенно зависит от их собственных предыдущих исходов. Однако есть такие команды УП, исход которых зависит от результатов выполнения других предшествующих им команд УП. Для таких случаев разработаны двухуровневые адаптивные схемы предсказания переходов, которые часто называют коррелированными, из-за учета взаимозависимости команд УП.
В коррелированных схемах предсказания переходов выделяют два уровня таблиц. В роли таблицы первого уровня обычно выступает регистр глобальной истории GHR или массив регистров локальной истории LHR. Каждый элемент таблицы второго уровня служит для хранения истории переходов отдельнойкоманды УП. Таблица второго уровня обычно состоит из двухразрядных счетчиков, которые организованы в виде матрицы.
Содержимое счетчика команд, в котором находится адрес команды УП, используется для определения одного из регистров в таблице первого уровня и одной строки в таблице второго уровня. Содержимое же выбранного регистра – шаблон, определяет порядковый номер счетчика в выбранной строке таблицы второго уровня. Найденный таким образом счетчик используется для предсказания обычным образом. После выполнения команды содержимое регистраи счетчикаобновляется.

В такой схеме выбор счетчика для предсказания зависит от двух источников: от адреса команды УП, для которой делается предсказание и от шаблона, который отражает историю переходов.
Гибридные схемы предсказания переходов
Точность предсказания в сильной степени зависит от особенностей конкретных программ. Одна и та же схема предсказания дает прекрасные результаты для одних программ и абсолютно неудовлетворительные для других. Поскольку точность предсказания повышается с увеличением глубины предыстории, необходимы дополнительные затраты времени на накопление соответствующей информации. Период накопления предыстории принято называть “временем разогрева”. Пока идет “разогрев” точность предсказания весьма низка. Поэтому не существуют таких стратегий предсказания, которые бы давали высокую точность предсказаний во всех ситуациях. Выходом из этого положения является применение гибридныхилисоревновательных схем, которые объединяют в себе несколько различных механизмов предсказания – элементарных предикторов. В каждой конкретной ситуации из множества предикторов выбирается тот элементарный предиктор, который может дать наибольшую точность предсказания.
Гибриднаясхема предсказания переходов, предложенная Макфарлингом, содержит два элементарных предиктора, отличающихся по своим характеристикам и работающих независимо друг от друга. Эти предикторы имеют разные размеры таблиц предыстории и разное время “разогрева”.
Выбор предиктора, наиболее подходящего в данной ситуации, обеспечивается селектором, представляющим собой таблицу двухразрядных счетчиков, которые называют счетчиками выбора предиктора.
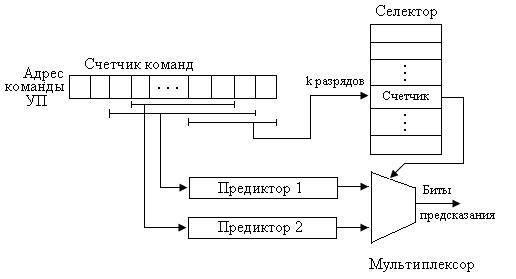
Выбор конкретного счетчика в таблице производится с помощью k младших разрядов адреса команды УП, для которой делается предсказание.
Обновление таблиц истории в каждом из предикторов производится обычным образом.
Изменение состояния счетчиков селектора выполняется по следующим правилам: если оба предиктора одновременно дали одинаковые предсказания, неважно верные или нет, содержимое счетчика не изменяется. При правильном предсказании от первого предиктора и неверном от второго содержимое счетчика селектораувеличивается, в противоположном случае – уменьшается на единицу. Выбор предиктора для предсказания реализуется с помощью мультиплексора, управляемого старшим разрядом соответствующего счетчика селектора.
Существуют и другие гибридныесхемы предсказания, точность которых в среднем составляет 97,13%, что существенно выше по сравнению с другими вариантами.
Суперконвейерные процессоры
Суперконвейеризациясводится к увеличению количества ступеней конвейера, как за счет добавления новых ступеней, так и путем дробления уже имеющихся ступеней на несколько простых подступеней. В каждой из подступеней операции реализуются с помощью наиболее простых технических средств и с минимальными затратами времени, что позволяет увеличить тактовую частоту внутри конвейера.
Рассмотрим работу суперконвейерного процессора на примере конвейера команд, в котором каждая из шести ступеней разбита на две более простые подступени, причем выполнение операции в подступенях занимает половину тактового периода.

Таким образом, девять команд на суперконвейере выполняются за десять тактов, тогда как на стандартном конвейере за 14 тактов (рис.1). Рост производительности на суперконвейере достигается за счет того, что в течении одного такта выполняется две команды.
Критерием для причисления процессора к суперконвейерному служит число ступеней в конвейере команд. К суперконвейерным относятся процессоры, в которых ступеней больше шести. Первым серийным суперконвейерным процессором считается MIPS R4000, в котором конвейер команд включал восемь ступеней. Количество ступеней в микропроцессорах Pentium фирмы Intel равно десяти для Pentium III и 20-ти Pentium IV.
Удлинение конвейера ведет не только к росту производительности, но и к росту проблем конвейеризации. В длинном конвейере возрастает вероятность конфликтов, дороже встает ошибка предсказания перехода, поскольку приходится очищать большее число ступеней, на что требуется дополнительное время. Усложняется также и логика взаимодействия ступеней конвейера между собой. Однако, несмотря на перечисленные проблемы, все большее количество фирм выпускают Суперконвейерные процессоры, успешно справляясь с трудностями конвейеризации.
Суперскалярные процессоры
Скалярными называются вычисления, операндами в которых выступают одиночные слова. Если в обработке данных участвуют многокомпонентные операнды типа векторов или матриц, компоненты которых обрабатываются одновременно, то говорят о векторных или матричныхпроцессорах.
Суперскалярным называется процессор, который одновременно выполняет более одной скалярной команды. Это достигается за счет включения в состав процессора нескольких самостоятельных функциональных блоков (АЛУ), каждый из которых отвечает за свой класс операций и может присутствовать в процессоре в нескольких экземплярах. Например, микропроцессор Pentium III содержит по два блока целочисленной арифметики и арифметики с плавающей точкой, а Pentium IV – по три таких блока. Структура типичного суперскалярного процессора имеет следующий вид:

Процессор включает в себя шесть блоков: выборки команд, декодирования команд, диспетчеризации команд, распределения команд по функциональным блокам (АЛУ), блок исполнения команд и блок обновления состояния.
Блок выборки команд извлекает команды программы из оперативной памяти через кэш-память команд. Этот блок содержит в своем составе счетчик команд и обрабатывает команды условного перехода совместно с блоком обработки ветвлений.
Блок декодирования дешифрирует код операции, извлеченной из кэш-памяти команд. В некоторых суперскалярных процессорах, например в микропроцессорах фирмы Intel, блоки выборки и декодирования команд совмещены.
Блоки диспетчеризации и распределения взаимодействуют между собой и в совокупности играют роль контроллера трафика (потока команд). Оба блока хранят очереди декодированных команд. Очередь блока распределения обычно распределена по нескольким самостоятельным буферам – накопителям команд, предназначенным для хранения декодированных, но еще не выполненных команд. Каждый накопитель команд связан со своим функциональным блоком (АЛУ), число которых обычно равно числу накопителей. Однако, если в процессоре используется несколько однотипных АЛУ, то им придается общий накопитель.
Кроме очереди команд, блок диспетчеризации хранит так же список свободных АЛУ. Этот список называют табло. Это табло используется для отслеживания состояния очереди распределения. Один раз за цикл обработки блок диспетчеризации извлекает команды из своей очереди, читает из кэш-памяти или из регистров операнды этих команд и в зависимости от состояния табло помещает команды и операнды в очередь распределения. Блок распределения в каждом цикле проверяет каждую команду в своих очередях на наличие всех необходимых для ее выполнения операндов. В случае готовности команда передается в блок исполнения, где и выполняется в соответствующем АЛУ.
Блок исполнения состоит из набора функциональных блоков (АЛУ). Примерами функциональных блоков могут служить целочисленные операционные блоки, блоки умножения и сложения с плавающей точкой, блок обращения к памяти. После исполнения команды, ее результат записывается в память и анализируется блоком обновления состояния, который передает полученный результат тем командам в очередях распределения, в которых этот результат выступает в качестве операнда.
Поскольку суперскалярность предполагает одновременную работу нескольких АЛУ, то для загрузки этих АЛУ процессор должен иметь в своем составе несколько конвейеров. Например, микропроцессоры Intel фирмы Pentium имеют два конвейера, каждый со своим АЛУ. В таком конвейере в каждом цикле необходимо производить выборку из памяти более чем одной команды. Поэтому память ЭВМ должна допускать одновременное чтение нескольких команд и операндов, что обеспечивается за счет ее многомодульного построения.
Блоки исполнения команд кроме АЛУ могут содержать специализированные устройства, позволяющие быстро выполнять такие операции как “Чтение”, “Запись”, “Переход”. Подобная форма суперскалярногопроцессора использовалась в микропроцессорах Pentium II и Pentium III фирмы Intel. В общем, применение суперскалярного процессора позволяет повысить производительность ЭВМ в 2–8 раз.
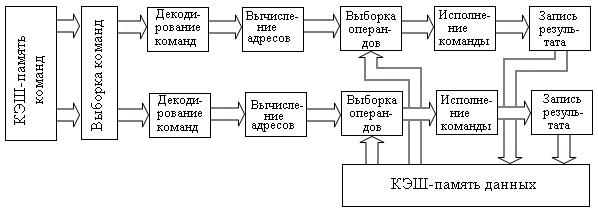
Рассмотрим работу суперскалярного конвейера со специализированными исполнительными блоками. Структурная схема такого конвейера имеет следующий вид: 
В таком конвейере блок выборки (ВК) читает из памяти более одной команды и передает прочитанные команды через ступени декодирования и вычисление адресов (ВА) в блок выборки операндов (ВО). После выборки операндов команды распределяются по соответствующим исполнительным блокам. Исполнительные блоки реализуют свои наборы команд.
Последнее изменение этой страницы: 2016-07-23
lectmania.ru. Все права принадлежат авторам данных материалов. В случае нарушения авторского права напишите нам сюда...