Категории:
ДомЗдоровьеЗоологияИнформатикаИскусствоИскусствоКомпьютерыКулинарияМаркетингМатематикаМедицинаМенеджментОбразованиеПедагогикаПитомцыПрограммированиеПроизводствоПромышленностьПсихологияРазноеРелигияСоциологияСпортСтатистикаТранспортФизикаФилософияФинансыХимияХоббиЭкологияЭкономикаЭлектроника
Классификация структур данных по признаку изменчивости
Введение
В последние годы программирование для персональных компьютеров вылилось в некоторую дисциплину, владение которой стало основным и ключевым моментом, определяющим успех многих инженерных проектов, а сама она превратилась в объект научного исследования. Из ремесла программирование перешло в разряд академических наук. Крупные специалисты в области программирования показали, что программы поддаются точному анализу, основанному на строгих математических рассуждениях. Убедительно продемонстрировано, что можно избежать многих ошибок, традиционных для программистов, если последние будут осмысленно пользоваться методами и приемами, которые раньше они применяли интуитивно, часто не осознавая их как таковые. При этом основное внимание ими обычно уделяется построению и анализу программы, а анализу и выбору представления данных, как правило, уделяется меньшее, явно второстепенное, внимание. На самом деле современная методология программирования предполагает, что оба аспекта программирования — запись алгоритма на языке программирования и выбор структур представления данных — заслуживают абсолютно одинакового внимания. Теперь всем, кто занят вопросами программирования для вычислительной техники, стало ясно, что решение о том, как представлять данные, невозможно принимать без понимания, того, какие алгоритмы будут к ним применяться, и наоборот, выбор алгоритма часто очень сильно зависит от строения данных, к которым он применяется.
Без знания структур данных и алгоритмов невозможно создать сколько-нибудь серьезный программный продукт. Ни одна информационная система не обходится без программного обеспечения, более того, она просто не может существовать без этой компоненты. Поэтому основная задача данной книги состоит в следующем:
• познакомить со всем разнообразием имеющихся структур данных, показать, как эти структуры реализованы в языках программирования;
• познакомить с операциями, которые выполняются над структурами данных;
• показать особенности структурного подхода к разработке алгоритмов, продемонстрировать порядок разработки алгоритмов.
Тщательно подобранный материал, вошедший в пособие, включает в себя основные, фундаментальные классы алгоритмов, которые в том или ином виде наиболее часто встречаются в практике программирования.
Ценность его в том, что оно предназначено не столько для обучения технике программирования, сколько для обучения, если это возможно, «искусству» программирования. Настоящее пособие предлагает массу рецептов усовершенствования программ и, что самое главное, учит самостоятельно находить эти рецепты.
Рассмотрены структуры данных, их представление и алгоритмы обработки, без знания которых невозможно современное компьютерное программирование. Приведены различные алгоритмы для работы с очередями, стеками, списками, деревьями, таблицами и графами. Алгоритмы большинства операций над структурами данных доведены до программной реализации в виде функций на языках Си и Turbo Pascal.
В конце каждой главы содержится большое количество контрольных вопросов и задач для самостоятельного решения.
Пособие предназначено для студентов, обучающихся по направлению и специальностям «Вычислительные машины, системы, комплексы и сети», «Автоматизированные системы обработки информации и управления», «Программное обеспечение вычислительной техники и автоматизированных систем».
Структурная организация данных
Обработка на персональных электронных вычислительных машинах (ПЭВМ) данных реального мира требует, чтобы их структура была определена и точно представлена в ПЭВМ. Структура данных определяет семантику данных, а также способы организации и управления данными. Информация, представленная в виде последовательности символов и предназначенная для обработки на ПЭВМ, называется данными. При использовании компьютера для хранения и обработки данных необходимо хорошо знать тип и структуру данных, а также найти способ наиболее естественного их представления. Структуры данных и алгоритмы служат теми материалами, из которых строятся программы.
Без понимания структур данных и алгоритмов невозможно создать серьезный программный продукт — «они служат базовыми элементами любой машинной программы. В организации структур данных и процедур их обработки заложена возможность проверки правильности работы программы» [4].
1.1. Основные понятия структур данных
В основе работы компьютера лежит умение оперировать только с одним видом данных — с отдельными битами, или двоичными цифрами. Работает же с этими данными компьютер только в соответствии с неизменным набором алгоритмов, которые определяются системой команд процессора. Задачи, которые решаются с помощью компьютера, редко выражаются на языке битов. Как правило, данные имеют форму чисел, литер, текстов, символов и более сложных структур типа последовательностей, списков и деревьев. Еще разнообразнее алгоритмы, применяемые для решения различных задач; фактически алгоритмов не меньше, чем вычислительных задач.
Структура данных относится по существу к пространственным понятиям: ее можно свести к схеме организации информации в памяти компьютера. Алгоритм же является соответствующим процедурным элементом в структуре программы — он служит рецептом расчета. Первые алгоритмы были придуманы для решения численных задач типа умножения чисел, нахождения наибольшего общего делителя, вычисления тригонометрических функций и др. Сегодня в равной степени важны и нечисленные алгоритмы; они разработаны для таких задач, как, например, поиск в тексте заданного слова, планирование событий, сортировка данных в указанном порядке и т. п. Нечисленные алгоритмы оперируют с данными, которые не обязательно являются числами.
Структуры данных, применяемые в алгоритмах, могут быть чрезвычайно сложными. В результате выбор правильного представления данных часто служит ключом к удачному программированию и может в большей степени сказываться на производительности программы, чем детали используемого алгоритма. Вряд ли когда-нибудь появится общая теория выбора структур данных. Самое лучшее, что можно сделать, — разобраться во всех базовых «кирпичиках» и собранных из них структурах. Способность приложить эти знания к конструированию больших систем — это, прежде всего дело инженерного мастерства и практики.
Независимо от содержания и сложности любые данные в памяти ЭВМ представляются последовательностью двоичных разрядов, или битов, а их значениями являются соответствующие двоичные числа. Данные, рассматриваемые в виде последовательности битов, имеют очень простую организацию или, другими словами, слабо структурированы. Для человека описывать и исследовать сложные данные в терминах последовательностей битов весьма неудобно. Более крупные и содержательные, нежели бит, «строительные блоки» для организации произвольных данных получаются на основе понятия «структуры данных».
Под структурой данныхв общем случае понимают множество элементов данных и множество связей между ними. Такое определение охватывает все возможные подходы к структуризации данных, но в каждой конкретной задаче используются те или иные его аспекты. Поэтому вводится дополнительная классификация структур данных, направления которой соответствуют различным аспектам их рассмотрения. Прежде чем приступать к изучению конкретных структур данных, дадим их общую классификацию по нескольким признакам. Понятие физическая структура данных отражает способ физического представления данных в памяти машины и называется еще структурой хранения, внутренней структурой или структурой памяти. Рассмотрение структуры данных без учета ее представления в машинной памяти называется абстрактной или логической структурой. В общем случае между логической и соответствующей ей физической структурами существует различие, которое зависит от самой структуры и особенностей той среды, в которой она должна быть отражена. Вследствие этого различия существуют процедуры, осуществляющие отображение логической структуры в физическую и, наоборот, физической структуры в логическую. Эти процедуры обеспечивают, кроме того, доступ к физическим структурам и выполнение над ними различных операций, причем каждая операция рассматривается применительно к логической или физической структуре данных.
Различают простые(базовые, примитивные) структуры (типы) данных и интегрированные(структурированные, композитные, сложные).
Простыминазываются такие структуры данных, которые не могут быть расчленены на составные части, большие, чем биты. С точки зрения физической структуры важным является то обстоятельство, что в данной машинной архитектуре, в данной системе программирования всегда можно заранее сказать, каков будет размер выбранного простого типа и какова структура его размещения в памяти. С логической точки зрения простые данные являются неделимыми единицами.
Интегрированныминазываются такие структуры данных, составными частями которых являются другие структуры данных — простые или в свою очередь интегрированные. Интегрированные структуры данных конструируются программистом с использованием средств интеграции данных, предоставляемых языками программирования.
В зависимости от отсутствия или наличия явно заданных связей между элементами данных следует различать несвязные структуры(векторы, массивы, строки, стеки, очереди) и связные структуры(связные списки).
Связные списки
Связный список— структура данных, элементами которой являются записи, связанные друг с другом с помощью указателей, хранящихся в самих элементах (рис. 1.2).
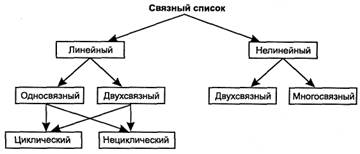
Рис. 1.2.Классификация связных списков
В зависимости от характера взаимного расположения элементов в памяти структуры данных можно разделить на структуры с последовательнымраспределением элементов в памяти (векторы, строки, массивы, стеки, очереди) и структуры с произвольным связнымраспределением элементов в памяти (односвязные, двухсвязные списки) (рис. 1.3).

Рис. 1.3.Представление структур данных в оперативной (а) и во внешней (б) памяти
В языках программирования понятие «структуры данных» тесно связано с понятием «типы данных». Любые данные, т. е. константы, переменные, значения функций или выражения, характеризуются своими типами. Информация по каждому типу однозначно определяет:
1) структуру хранения данных указанного типа, т. е. выделение памяти и представление данных в ней, с одной стороны, и интерпретирование двоичного представления, с другой;
2) множество допустимых значений, которые может иметь тот или иной объект описываемого типа;
3) множество допустимых операций, которые применимы к объекту описываемого типа.
Над всеми структурами данных могут выполняться четыре операции: создание; уничтожение; выбор (доступ); обновление.
Операция созданиязаключается в выделении памяти для структуры данных. Память может выделяться в процессе выполнения программы при первом появлении имени переменной в исходной программе или на этапе компиляции. В ряде языков для структурированных данных, конструируемых программистом, операция создания включает в себя также установку начальных значений параметров создаваемой структуры. Для структур данных, объявленных в программе, память выделяется автоматически средствами системы программирования либо на этапе компиляции, либо при активизации процедурного блока, в котором объявляются переменные. Программист может и сам выделять память для структур данных, используя имеющиеся в системе программирования соответствующие средства для выделения и освобождения памяти. В объектно-ориентированных языках программирования при разработке нового объекта для него должны быть определены процедуры его создания и уничтожения.
Операция уничтоженияструктур данных противоположна по своему действию операции создания. Операция уничтожения помогает эффективно использовать память.
Операция выбораиспользуется программистами для доступа к данным внутри самой структуры. Форма операции доступа зависит от типа структуры данных, к которой осуществляется обращение. Метод доступа — одно из наиболее важных свойств структур, особенно в связи с тем, что это свойство имеет непосредственное отношение к выбору конкретной структуры данных.
Операция обновленияпозволяет изменить значения данных в структуре данных. Примером операции обновления является операция присваивания, или, более сложная форма — передача параметров.
Вышеуказанные четыре операции обязательны для всех структур и типов данных. Помимо этих общих операций для каждой структуры данных могут быть определены специфические операции, работающие только с данными указанного типа (данной структуры). Специфические операции анализируются при рассмотрении каждой конкретной структуры данных.
Методы сортировки
Упорядочение элементов множества в возрастающем или убывающем порядке называется сортировкой.
С упорядоченными элементами проще работать, чем с произвольно расположенными: легче найти необходимые элементы, исключить, вставить новые. Сортировка применяется при трансляции программ, при организации наборов данных на внешних носителях, при создании библиотек, каталогов, баз данных и т. д.
Алгоритмы сортировки можно разбить на следующие группы (рис. 2.1).
Обычно сортируемые элементы множества называют записями и обозначают через k1, k2, ..., kn.

Рис. 2.1.Алгоритмы сортировки
Сортировка выбором
Сортировка выбором состоит в том, что сначала в неупорядоченном списке выбирается и отделяется от остальных наименьший элемент. После этого исходный список оказывается измененным. Измененный список принимается за исходный и процесс продолжается до тех пор, пока все элементы не будут выбраны. Очевидно, что выбранные элементы образуют упорядоченный список.
Например, требуется найти минимальный элемент списка:
{5, 11, 6, 4, 9, 2, 15, 7}.
Процесс выбора показан на рис. 2.2, где в каждой строчке выписаны сравниваемые пары. Выбираемые элементы с меньшим весом обведены кружком. Нетрудно видеть, что число сравнений соответствует на рисунке числу строк, а число перемещений — количеству изменений выбранного элемента.
{5, 11, 6, 4, 9, 2,15, 7}

Рис. 2.2. Сортировка выбором
Выбранный в исходном списке минимальный элемент размещается на предназначенном ему месте несколькими способами:
• минимальный элемент после i-го просмотра перемещается на i-е место нового списка (i= 1, 2, ..., n), а в исходном списке на место выбранного элемента записывается какое-то очень большое число, превосходящее по величине любой элемент списка, при этом длина заданного списка остается постоянной. Измененный таким образом список можно принимать за исходный;
• минимальный элемент записывается на i-е место исходного списка (i= 1, 2, ...., п), а элемент с i-го места — на место выбранного. При этом очевидно, что уже упорядоченные элементы (а они будут расположены начиная с первого места) исключаются из дальнейшей сортировки, поэтому длина каждого последующего списка (списка, участвующего в каждом последующем просмотре) должна быть на один элемент меньше предыдущего;
• выбранный минимальный элемент, как и в предыдущем случае, перемещается на i-е место заданного списка, а чтобы это i-eместо освободилось для записи очередного минимального элемента, левая от выбранного элемента часть списка перемещается вправо на одну позицию так, чтобы заполнилось место, занимаемое до этого выбранным элементом (элементы списка циклически сдвигаются).
Сложность метода сортировки выбором порядка составляет О(n2).
Сортировка вставкой
В этом методе из неупорядоченной последовательности элементов выбирается поочередно каждый элемент, сравнивается с предыдущим, уже упорядоченным, и помещается на соответствующее место.
Сортировку вставкой рассмотрим на примере заданной неупорядоченной последовательности элементов: {40, 11, 83, 57, 32, 21, 75, 64}.
Процедура сортировки отражена на рис. 2.3, где кружком на каждом этапе обведен анализируемый элемент, стрелкой сверху отмечено место перемещения анализируемого элемента, в рамку заключены упорядоченные части последовательности.
На первом этапе сравниваются два начальных элемента. Поскольку второй элемент меньше первого, он перемещается на место первого элемента, который сдвигается вправо на одну позицию. Остальная часть последовательности остается без изменения.
На втором этапе из неупорядоченной последовательности выбирается элемент и сравнивается с двумя упорядоченными ранее элементами. Так как он больше предыдущих, то остается на месте. Затем анализируются четвертый, пятый и последующие элементы — до тех пор, пока весь список не будет упорядоченным, что имеет место на последнем (седьмом) этапе.

Рис. 2.3. Сортировка вставкой
Сортировка слиянием
Разновидностью сортировки вставкой является метод фон Неймана.
Алгоритм решения этой задачи, известный как «сортировка фон Неймана» или сортировка слиянием, состоит в следующем: сначала анализируются первые элементы обоих массивов. Меньший элемент переписывается в новый массив. Оставшийся элемент последовательно сравнивается с элементами из другого массива. В новый массив после каждого сравнения попадает меньший элемент. Процесс продолжается до исчерпания элементов одного из массивов. Затем остаток другого массива дописывается в новый массив. Полученный новый массив упорядочен таким же образом, как исходные.
Пусть имеются два отсортированных в порядке возрастания массива р[1], р[2], ..., р[n]и q[l], q[2], ..., q[n]иимеется пустой массив r[1], r[2], ..., r[2n], который необходимо заполнить значениями массивов р и q в порядке возрастания. Для слияния выполняются следующие действия: сравниваются р[1]и q[1], и меньшее из значений записывается в r[1]. Предположим, что это значение р[1]. Тогда р[2]сравнивается с q[1]и меньшее из значений заносится в r[2]. Предположим, что это значение q[1]. Тогда на следующем шаге сравниваются значения р[2]и q[2]и т. д., пока не достигнута граница одного из массивов. Тогда остаток другого массива просто дописывается в «хвост» массива r.
Пример слияния двух массивов показан на рис. 2.4.
Сложность метода сортировки вставкой порядка 0(п2).

Рис. 2.4.Сортировка слиянием
Сортировка обменом
Сортировка обменом — метод, в котором элементы списка последовательно сравниваются между собой и меняются местами в том случае, если предшествующий элемент больше последующего.
Требуется, например, провести сортировку списка методом стандартного обмена или методом «пузырька»:
{40, 11, 83, 57, 32, 21, 75, 64}.
Обозначим квадратными скобками со стрелками ↑____↑ обмениваемые элементы, а |____| — сравниваемые элементы. Первый этап сортировки показан на рис. 2.5, а второй этап — на рис. 2.6.
Нетрудно видеть, что после каждого просмотра списка все элементы, начиная с последнего, занимают свои окончательные позиции, поэтому их не следует проверять при следующих просмотрах. Каждый последующий просмотр исключает очередную позицию с найденным максимальным элементом, тем самым укорачивая список.
После первого просмотра в последней позиции оказался больший элемент, равный 83 (исключаем его из дальнейшего рассмотрения).
Второй просмотр выявляет максимальный элемент, равный 75 (см. рис. 2.6).

Рис. 2.5. Сортировка обменом (первый просмотр)

Рис. 2.6.Сортировка обменом (второй просмотр)
Процесс сортировки продолжается до тех пор, пока не будут сформированы все элементы конечного списка либо не выполнится условие Айверсона.
Условие Айверсона:если в ходе сортировки при сравнении элементов не было сделано ни одной перестановки, то множество считается упорядоченным (условие Айверсона выполняется только при шаге d= 1).
Шейкерная сортировка
Модификацией сортировки стандартным обменом является шейкернаяили челночная сортировка. Здесь, как и в методе пузырька, проводится попарное сравнение элементов. При этом первый проход осуществляется слева направо, второй — справа налево и т. д. Иными словами, меняется направление просмотра элементов списка.
Сложность метода стандартного обмена — 0(п2).
Сортировка Шелла
В методе Шелла сравниваются не соседние элементы, а элементы, расположенные на расстоянии d = [n/2] (где d — шаг между сравниваемыми элементами, [ ] — целая часть от числа). После каждого просмотра шаг d уменьшается вдвое. На последнем просмотре он сокращается до d= 1.
Например, пусть дан список, в котором число элементов четно:
{40, 11, 83, 57, 32, 21, 75, 64}.
Список длины п разбивается на n/2 частей, т. е. d = [n/2] = 4.
При первом просмотре сравниваются элементы, отстоящие друг от друга на d= 4 (рис. 2.7), т. е. k1 и k5, k2 и k6 и т. д. Если ki> ki+d, то происходит обмен между позициями i и (i + d). Перед вторым просмотром выбирается шаг d = [d/2] = 2 (рис. 2.8). Затем выбираем шаг d= [d/2] = 1 (рис. 2.9), т. е. имеем аналогию с методом стандартного обмена.
Сложность метода Шелла — O(0,3n(lоg2n)2).

Рис. 2.7. Метод Шелла (шаг d= 4)

Рис. 2.8.Метод Шелла (шаг d= 2)

Рис. 2.9.Метод Шелла (шаг d= 1)
2.1.5. Быстрая сортировка (сортировка Хоара)
В методе быстрой сортировки фиксируется какой-либо ключ (базовый), относительно которого все элементы с большим весом перебрасываются вправо, а с меньшим — влево. При этом весь список элементов делится относительно базового ключа на две части. Для каждой части процесс повторяется.
Поясним метод на примере.
На рис. 2.10 представлен первый этап быстрой сортировки. В первой строке указана исходная последовательность.
Примем первый элемент последовательности за базовый ключ, выделим его квадратом и обозначим k0 = 40. Установим два указателя: i и j, из которых i начинает отсчет слева (i=1), а j — справа (j= п).
Сравниваем базовый ключ k0 и текущий ключ kj. Если k0<= kj, то устанавливаем j =j - 1 и проводим следующее сравнение k0 и kj. Продолжаем уменьшать j до тех пор, пока не достигнем условия k0 > kj. После этого меняем местами ключи k0 и kj (шаг 3 на рис. 2.10).
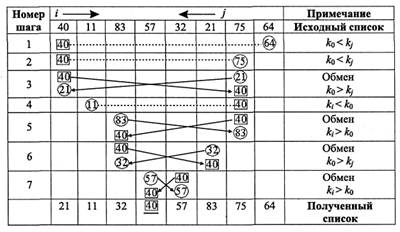
Рис. 2.10.Метод Хоара
Теперь начинаем изменять индекс i = i + 1 и сравнивать элементы ki и k0. Продолжаем увеличение i до тех пор, пока не получим условие ki > k0, после чего следует обмен ki и k0 (см. шаг 5). Снова возвращаемся к индексу j, уменьшаем его. Чередуя уменьшение j и увеличение i, продолжаем этот процесс с обоих концов к середине до тех пор, пока не получим i = j (см. шаг 7). В отличие от предыдущих рассмотренных сортировок уже на первом этапе имеют место два факта: во-первых, базовый ключ k0 = 40 занял свое постоянное место в сортируемой последовательности; во-вторых, все элементы слева от k0 будут меньше него, а справа — больше него. Таким образом, по окончании первого этапа имеем:

Указанная процедура сортировки применяется независимо к левой и правой частям.
Сложность метода Хоара — О(nlоg2n).
Турнирная сортировка
Свое название эта сортировка получила потому, что она используется при проведении соревнований, турниров и олимпиад. Элементы исходного множества представляются листьями дерева. Их попарное сравнение позволяет определить максимальный элемент.
Пример.Дано исходное множество {7, 1, 9, 3, 6, 5, 8}. Осуществить турнирную сортировку. Производится попарное сравнение вершин дерева снизу вверх. Найденный максимальный элемент помещается в результирующее множество (рис. 2.11).

Рис. 2.11.Турнирная сортировка
В результате будет получено упорядоченное множество
{9, 8, 7, 6, 5, 3}.
Пирамидальная сортировка
Данный тип сортировки заключается в построении пирамидального дерева.
Пирамидальное дерево — это бинарное дерево, обладающее тремя свойствами:
• в вершине каждой триады располагается элемент с большим весом;
• листья бинарного дерева располагаются либо в одном уровне, либо в двух соседних (рис. 2.12);
• листья нижнего уровня располагаются левее листьев более высокого уровня.

Рис. 2.12.Бинарное дерево:
а — листья на одном уровне; 6 — листья на соседних уровнях
В ходе преобразования элементы триад сравниваются дважды (рис. 2.13), при этом элемент с большим весом перейдет вверх, а с меньшим — вниз.
Рис. 2.13.Сравнение элементов триад:
1 — первое сравнение; 2 — второе сравнение
Пример.Дано исходное множество {2, 4, 6, 3, 5, 7}. Метод пирамидальной сортировки показан на рис. 2.14.

Рис. 2.14.Пирамидальная сортировка
В результате будет получено упорядоченное множество {2, 3, 4, 5, 6, 7}.
Функция сложности алгоритма
Для оценки эффективности алгоритмов используется функция сложности алгоритма, которая обозначается прописной буквой О, в круглых скобках записывается аргумент. Например, функция сложности О(п2) читается как функция сложности порядка n2. Функция сложности алгоритма — это функция, которая определяет количество сравнений, перестановок, а также временные и ресурсные затраты на реализацию алгоритма. Функция сложности принимает следующий ряд значений (рис. 2.15).
n nlog2n n2 n3 en n!
 |
Рис. 2.15.Ряд значений функции сложности алгоритма
Чем правее на оси расположена функция сложности, тем менее эффективен алгоритм.
Методы простая вставка, простой и стандартный обмен имеют функцию сложности O(п2).
Метод Хоара и пирамидальная сортировка имеют функцию сложности O(nlog2n).
Метод Шелла и турнирная сортировка "имеют функцию сложности O(0,3n(log2n)2).
Контрольные вопросы
Методы поиска
Предметы (объекты), составляющие множество, называются его элементами. Элемент множества будет называться ключом и обозначаться латинской буквой «k» с индексом, указывающим номер элемента.
Алгоритмы поиска можно разбить на следующие группы (рис. 2.16).
Задача поиска.
Пусть задано множество ключей {k1,, k2, k3, ..., kn}.
Необходимо отыскать во множестве ключ ki. Поиск может быть завершен в двух случаях:
• ключ во множестве отсутствует;
• ключ найден во множестве.
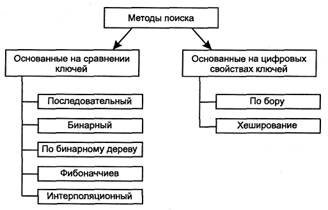
Рис. 2.16.Методы поиска
2.2.1. Последовательный поиск
В последовательном поиске исходное множество не упорядочение, т. е. имеется произвольный набор ключей {k1; k2, k3, ..., kn,}. Метод заключается в том, что отыскиваемый ключ ki последовательно сравнивается со всеми элементами множества. При этом поиск заканчивается досрочно, если ключ найден.
2.2.2. Бинарный поиск
В бинарном поиске исходное множество должно быть упорядочено по возрастанию. Иными словами, каждый последующий ключ больше предыдущего, т. е.
{k1≤k2≤k3≤k4...kn-1≤kn}.
Отыскиваемый ключ сравнивается с центральным элементом множества, если он меньше центрального, то поиск продолжается в левом подмножестве, в противном случае — в правом.
Номер центрального элемента находится по формуле
№ эл-та= [n/2] + 1,
где квадратные скобки обозначают, что от деления берется только целая часть (всегда округляется в меньшую сторону). В методе бинарного поиска анализируются только центральные элементы.
Пример.Дано множество
{7, 8, 12, 16, 18, 20, 30, 38, 49, 50, 54, 60, 61, 69, 75, 79, 80, 81, 95, 101, 123, 198}.
Найти во множестве ключ К= 61.
Шаг 1. № эл-та = [n/2] + 1 = [22/2] + 1 = 12.
K~k12.
61 > 60. Дальнейший поиск в правом подмножестве
(61, 69, 75, 79, 80, 81, 95, 101, 123, 198}.
Значок «~» обозначает сравнение элементов (чисел, значений).
Шаг 2. № эл-та = [n/2] + 1 = [10/2] + 1=6.
К~ k18.
61 < 81. Дальнейший поиск в левом подмножестве
{61, 69, 75, 79, 80}
(относительно предыдущего подмножества).
Шаг 3. № эл-та = [n/2] + 1 = [5/2] + 1 = 3.
K~kl5.
61 < 75. Дальнейший поиск в левом подмножестве
{61, 69}.
Шаг 4. № эл-та = [n/2] + 1 = [2/2] + 1=2.
K~k14.
61 < 69. Дальнейший поиск в левом подмножестве
{61}.
Шаг 5. № эл-та = [n/2]+ 1 = [1/2] + 1 = 1.
K~kl3.
61 = 61.
Вывод: искомый ключ найден под номером 13.
Фибоначчиев поиск
В этом поиске анализируются элементы, находящиеся в позициях, равных числам Фибоначчи. Числа Фибоначчи получаются по следующему правилу:
каждое последующее число равно сумме двух предыдущих чисел, например:
{1, 2, 3, 5, 8, 13, 21, 34, 55, ...}.
Поиск продолжается до тех пор, пока не будет найден интервал между двумя ключами, где может располагаться отыскиваемый ключ.
Пример.Дано исходное множество ключей (3, 5, 8, 9, 11, 14, 15, 19, 21, 22, 28, 33, 35, 37, 42, 45, 48, 52}.
Пусть отыскиваемый ключ равен 42 (К= 42).
Последовательное сравнение отыскиваемого ключа будет проводиться в позициях, равных числам Фибоначчи: {1, 2, 3, 5, 8, 13, 21,...}.
Шаг 1. К~ Ki, 42 > 3 => отыскиваемый ключ сравнивается с ключом, стоящим в позиции, равной числу Фибоначчи.
Шаг 2. К~ К2, 42 > 5 => сравнение продолжается с ключом, стоящим в позиции, равной следующему числу Фибоначчи.
Шаг 3. К~ К3, 42 > 8 => сравнение продолжается.
Шаг 4. К~ К5, 42 > 11 => сравнение продолжается.
Шаг 5. К~ K8, 42 > 19 => сравнение продолжается.
Шаг 6. К~ K13, 42 > 35 => сравнение продолжается.
Шаг 7. К~ К18, 42 < 52 => найден интервал, в котором находится отыскиваемый ключ: от 13 до 18 позиции, т. е. {35, 37, 42, 45, 48, 52}.
В найденном интервале поиск вновь ведется в позициях, равных числам Фибоначчи.
2.2.4. Интерполяционный поиск
Исходное множество должно быть упорядочено по возрастанию весов. Первоначальное сравнение осуществляется на расстоянии шага d, который определяется по формуле:
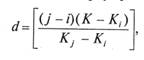
где i — номер первого рассматриваемого элемента; j — номер последнего рассматриваемого элемента; К — отыскиваемый ключ; Кi Kj — значения ключей в i и j позициях;
[ ] — целая часть от числа.
Идея метода заключается в следующем: шаг d меняется после каждого этапа по формуле, приведенной выше (рис. 2.17). Алгоритм заканчивает работу при d= 0, при этом анализируются соседние элементы, после чего делается окончательное решение о результатах поиска.

Рис. 2.17. Алгоритм поиска
Этот метод прекрасно работает, если исходное множество представляет собой арифметическую прогрессию или множество, приближенное к ней.
Пример.Дано множество ключей:
{2, 9, 10, 12, 20, 24, 28, 30, 37, 40, 45, 50, 51, 60, 65, 70, 74, 76}.
Пусть искомый ключ равен 70 (К= 70).
Шаг 1. Определим шаг d для исходного множества ключей:
d=[(18-l)(70-2)/(76-2)] = 15.
Сравниваем ключ, стоящий под шестнадцатым порядковым номером в данном множестве, с искомым ключом: К16 ~ К, 70 = 70, ключ найден.
Поиск по бинарному дереву
Использование структуры бинарного дерева позволяет быстро вставлять и удалять записи и производить эффективный поиск по таблице. Такая гибкость достигается добавлением в каждую запись двух полей для хранения ссылок.
Пусть дано бинарное дерево поиска (рис. 2.18).
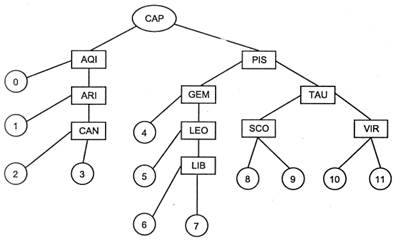
Рис.2.18. Бинарное дерево
Требуется по бинарному дереву отыскать ключ SAG.
При просмотре от корня дерева видно, что по первой букве латинского алфавита название SAG больше чем САР. Следовательно, дальнейший поиск будем осуществлять в правой ветви. Это слово больше, чем PIS, — снова идем вправо; оно меньше, чем TAU, — идем влево; оно меньше, чем SCO, и попадаем в узел 8. Таким образом, название SAG должно находиться в узле 8.
При этом узлы дерева имеют следующую структуру (табл. 2.1).
Таблица 2.1. Структура узлов дерева

Пример.Исходное множество ключей должно быть упорядочено по возрастанию. Переходим от линейного списка к по-1 строению бинарного дерева поиска (рис. 2.19), где корнем дерева является центральный элемент множества

где N — количество элементов множества.

Рис. 2.19.Бинарное дерево поиска
Вершиной по левой ветке является центральный элемент левого подмножества, а правой — правого подмножества и т. д. Пусть задано множество
{2, 4, 5, 6, 7, 9, 12, 14, 18, 21, 24, 25, 27, 30, 32, 33, 34, 37, 39};
Искомый ключ К= 24;
Всего элементов N= 19; Nцентр = [19/2] +1 = 10.
Поиск ключа К = 24 по бинарному дереву от корня до листьев показан на рис. 2.19.
Поиск хешированием
В основе поиска лежит переход от исходного множества к множеству хеш-функций h(k).
Хеш-функция имеет следующий вид:
h(k) = kmod(m),
где k — ключ; т — целое число; mod — целочисленный остаток от деления.
Например, пусть дано множество {9, 1, 4, 10, 8, 5}.
Определим для него хеш-функцию h(k) = kmod(m):
• пусть т = 1, тогда
h(k) = {0, 0, 0, 0, 0, 0};
• пусть т = 20, тогда
h(k) = {9, 1, 4, 10, 8, 5};
• пусть т равно половине максимального ключа, тогда т = = [10/2] = 5
h(k) = {4,1, 4, 0, 3, 0}.
Хеш-функция указывает адрес, по которому следует отыскивать ключ. Для разных ключей хеш-функция может принимать одинаковые значения, такая ситуация называется коллизией. Таким образом, поиск хешированием заключается в устранении коллизий методом цепочек (рис. 2.22).
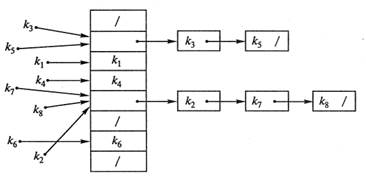
Рис. 2.22. Устранение коллизий методом цепочек
Пример.Дано множество
{7, 13, 6, 3, 9, 4, 8, 5}.
Найти ключ К=27.
Хеш-функция равна h(k} = Kmod(m);
т = [13/2] = 6 (так как 13 — максимальный ключ).
h(k) = {1, 1, 0, 3, 3, 4, 2, 5}.
Для устранения коллизий построим табл. 2.5.
Попарным сравнением множества хеш-функций и множества исходных ключей заполняем таблицу.
Напоминаем, что хеш-функция указывает адрес, по которому следует отыскивать ключ.
Таблица 2.5. Разрешение коллизий

Например, если отыскивае
Последнее изменение этой страницы: 2016-07-23
lectmania.ru. Все права принадлежат авторам данных материалов. В случае нарушения авторского права напишите нам сюда...