Категории:
ДомЗдоровьеЗоологияИнформатикаИскусствоИскусствоКомпьютерыКулинарияМаркетингМатематикаМедицинаМенеджментОбразованиеПедагогикаПитомцыПрограммированиеПроизводствоПромышленностьПсихологияРазноеРелигияСоциологияСпортСтатистикаТранспортФизикаФилософияФинансыХимияХоббиЭкологияЭкономикаЭлектроника
Oбщее описание алгоритма кодирования речевого сигнала СЕLР
Для кодирования (информационного уплотнения) речевых сигналов в стандарте ТЕТRА используется кодер с линейным предсказанием и многоимпульсным возбуждением от кода - СЕLР (Соdе Ехсited Linear Ргеdiction). Данный метод кодирования основан на линейной авторегрессионной модели процесса формирования и восприятия речи и входит в группу т.н. методов анализа через синтез, реализующих современные и эффективные алгоритмы информационного уплотнения речевых сигналов. Алгоритмы данного класса занимают промежуточное положение между кодерами формы сигнала, в которых сохраняется форма колебания речевого сигнала в процессе его дискретизации и квантования, и параметрическими вокодерами, основанными на процедурах оценки и кодирования небольшого числа параметров речи, объединяя преимущества каждого из них.
Линейная авторегрессионная модель процесса формирования речевых сигналов с локально постоянными на интервалах 10-30 мс параметрами получила в настоящее время наибольшее распространение. Для этой модели:
 (1),
(1),
где М - порядок модели, s(п) - последовательность отсчетов речевого сигнала, а(т) - коэффициенты линейного предсказания, характеризующие свойства голосового тракта, а х(п) - порождающая последовательность или сигнал возбуждения голосового тракта. Авторегрессионная модель речевого сигнала описывает его с достаточно высокой степенью точности и позволяет применять развитый математический аппарат линейного предсказания. При этом обеспечивается более высокое качество декодированной речи, устойчивость к входному акустическому шуму и ошибкам в канале связи, чем в системах с иными принципами кодирования.
В рамках данной модели наиболее перспективными методами кодирования считаются методы анализа через синтез с использованием многоимпульсного возбуждения от кода. Новизна многоимпульсного возбуждения заключается в том, что в сигнале остатка линейного предсказания выбираются такие его значения, которые наиболее важны для повышения качества синтезированной речи. При этом используемая в процедуре анализа через синтез схема кодирования, помимо учета ошибок квантования, включает критерии субъективной оценки качества речевого сигнала, что обеспечивает естественное звучание синтезированной речи.
При многоимпульсном возбуждении сигнал остатка линейного предсказания представляется в виде последовательности импульсов с неравномерно распределенными интервалами и с различными амплитудами (около 8-10 импульсов за 10 мс). Амплитуды и положения этих импульсов определяются на покадровой основе (кадр за кадром). Основным преимуществом многоимпульсного возбуждения является то, что оно определяется для любого речевого сегмента и при этом не требуется знаний ни о вокализованности данного сегмента, ни о периоде основного тона.
Методы анализа через синтез используют синтезатор (декодер) речевого сигнала как составную часть устройства кодирования. При этом задача анализа сводится к процедуре оценки передаваемых в канал связи параметров речи, проводимой в соответствии с некоторым критерием рассогласования между исходным и декодированным сигналами. Для учета специфики слухового восприятия в качестве критерия рассогласования обычно используется взвешенная по частоте квадратическая ошибка
 (2),
(2),
где S(f) и Sq(f) - преобразование Фурье исходного и синтезированного речевых сигналов, a W(f) -весовая функция. Принимая во внимание важность для восприятия речи не только формант, но и межформантных областей, для алгоритмов анализа речи через синтез Этолом была предложена весовая функция следующего вида
 (3),
(3),
где A-1(z) - синтезирующий фильтр, а  - параметр, регулирующий энергию ошибки или шум квантования. Фактически при таком взвешивании подчеркивается ошибка в межформантных областях и тем самым обеспечивается более равномерное по частоте распределение отношения мощности полезного сигнала к мощности ошибки кодирования.
- параметр, регулирующий энергию ошибки или шум квантования. Фактически при таком взвешивании подчеркивается ошибка в межформантных областях и тем самым обеспечивается более равномерное по частоте распределение отношения мощности полезного сигнала к мощности ошибки кодирования.
В алгоритмах кодирования с анализом через синтез повышение эффективности информационного уплотнения речевых сигналов производится, преимущественно, за счет сокращения избыточности последовательности х(п), которая осуществляет возбуждение синтезирующего фильтра A-1(z) линейного предсказания, формирующего огибающую сигнала, с коэффициентом передачи
 (4).
(4).
Для этой цели применяется также дополнительный фильтр с характеристикой
 (5),
(5),
с одним коэффициентом предсказания gp и задержкой на период основного тона Т. Он выполняет функции генератора квазипериодических колебаний голосовых связок при произношении вокализованных звуков.
В зависимости от способа описания сигнала х(п), поступающегона вход фильтра (5), можно выделить алгоритмы кодирования с возбуждением прореженной последовательностью импульсов - MPLP (Multi Pulses Linear Prediction), с самовозбуждением - SELP (Self Excited Linear Prediction), и наконец, с возбуждением от кода - CELP. Экспериментально установлено, что кодовое возбуждение обеспечивает наиболее высокое качество декодированного речевого сигнала, в том числе и при наличии входных акустических помех.
Метод CELP был предложен Этолом и Шредером в 1984 г. Наиболее эффективно применение этого метода при передаче речевого сигнала в диапазоне скоростей от 4 до 16 Кбит/с.
Базовая структурная схема передающей (а) и приемной (б) частей CELP-кодера показана на рис. 1.

Рис. 7.1. Структурная схема передающей и приемной частей CELP-кодера
По существу, в алгоритме CELP производится векторное квантование последовательности х(п), т.е. позиции импульсов и их амплитуды в сигнале многоимпульсного возбуждения оптимизируются одновременно. При этом отрезок (сегмент) сигнала возбуждения выбирается из предварительно сформированной постоянной совокупности - кодовой книги, содержащей достаточно большое количество реализаций, например, некоррелированного гауссовского шума. Выбранная реализация усиливается и подается на вход цепочки фильтров (5) и (4).
Поиск оптимальных значений gp и Т синтезатора основного тона, коэффициента усиления и номера элемента кодовой книги осуществляется посредством анализа через синтез. В целом, в канал связи передаются номер (индекс) элемента кодовой книги с соответствующим коэффициентом усиления, параметры синтезатора основного тона, а также коэффициенты линейного предсказания, характеризующие состояние голосового тракта.
Структура кодера TETRA
В стандарте TETRA используется CELP-кодер со скоростью преобразования 4,8 Кбит/с. На рис. 2 показана упрощенная блок-схема декодера (синтезатора), используемого в CELP-кодере TETRA.
Основными узлами схемы декодера являются 2 синтезирующих фильтра с большой и малой постоянной времени и алгебраическая кодовая книга.
Фильтр с большой постоянной времени выполняет функцию долговременного предиктора (Long Term Preductor), моделирует квазипериодичность (долговременные корреляции) речевого сигнала и имеет характеристику (5). Он выполнен на основе адаптивной кодовой книги, содержащей сигналы возбуждения и реализующей генерацию квазипериодических колебаний голосового тракта.
Фильтр с малой постоянной времени выполняет функцию кратковременного предиктора (Short Term Preductor), моделирует кратковременные корреляции, т.е. корреляции между отсчетами речевого сигнала, и имеет характеристику (4) с порядком предсказывающего устройства, соответствующим М=10. В синтезаторе TETRA используется весовая функция (3) со значением коэффициента =0,85.
Алгебраическая (постоянная) кодовая книга содержит совокупность векторов возбуждения, представляющих собой последовательности с белым гауссовским распределением с нулевым средним значением и единичной дисперсией. Она служит для реализации первого этапа генерации возбуждающего сигнала. На втором этапе производится коррекция возбуждающего сигнала путем добавления к нему данных из адаптивной кодовой книги. Сформированная в итоге возбуждающая последовательность поступает на вход синтезирующего фильтра A-1(z), где вычисляются значения выходного речевого сигнала в соответствии с выражением (1).
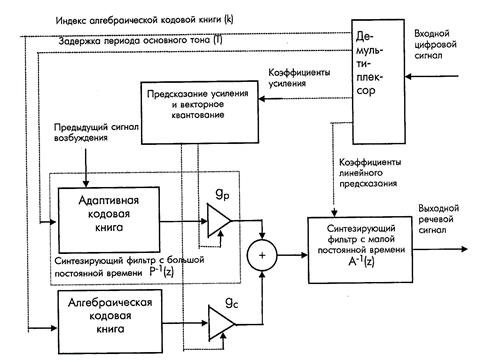
Рис. 2. Блок-схема декодера речевого сигнала в стандарте TETRA
В кодере TETRA производится оценка М=10 коэффициентов линейного предсказания и анализ возможных значений параметра синтезатора (индекса kc и коэффициента усиления gc алгебраической кодовой книги и индекса kp и коэффициента усиления gp адаптивной кодовой книги), целью которого является минимизация взвешенной ошибки рассогласования между входным и синтезированным речевыми сигналами. Полученные при этом оптимальные параметры синтезатора квантуются и передаются в канал связи. Обработка сигналов в кодере и декодере производится по блокам. Длительность основного блока составляет 30 мс, что соответствует 240 отсчетам при частоте дискретизации 8 кГц. Для каждого такого блока формируется кадр передаваемой в канал связи информации объемом 137 бит, что обеспечивает скорость передачи информации 4567 бит/с. Оценка коэффициентов линейного предсказания выполняется один раз на всем блоке, а оптимизация остальных параметров синтезатора выполняется на сегментах длительностью 60 отсчетов, т.е. 4 раза на блок. Поразрядное распределение информации в передаваемом кадре приведено в табл. 1.
Таблица1.
| Параметр | 1-й сегмент | 2-й сегмент | 3-й сегмент | 4-й сегмент | Всего в кадре |
| Коэффициенты линейного предсказания | |||||
| Период основного тона | |||||
| Индекс алгебраической кодовой книги | |||||
| Коэффициенты усиления | |||||
| Всего |
КАНАЛЬНОЕ КОДИРОВАНИЕ
Последнее изменение этой страницы: 2016-07-22
lectmania.ru. Все права принадлежат авторам данных материалов. В случае нарушения авторского права напишите нам сюда...