Категории:
ДомЗдоровьеЗоологияИнформатикаИскусствоИскусствоКомпьютерыКулинарияМаркетингМатематикаМедицинаМенеджментОбразованиеПедагогикаПитомцыПрограммированиеПроизводствоПромышленностьПсихологияРазноеРелигияСоциологияСпортСтатистикаТранспортФизикаФилософияФинансыХимияХоббиЭкологияЭкономикаЭлектроника
Вокодер как цифровая модель речевого тракта
Введение
Вокодеры – это системы параметрического кодирования речи, широко применяемые в современной цифровой телефонной связи, в том числе – Internet-телефонии [1,2]. Причиной тому – высокая степень сжатия информации, а также хорошая согласованность вокодеров с системами канального кодирования и шифрования, в результате чего сравнительно легко обеспечивается высокая защищенность систем связи от помех и утечки информации. Недостатком вокодеров является невысокое качество речи, поэтому они применяются главным образом в военной связи, где главное – не натуральность речи, а ее высокая степень сжатия и хорошая разборчивость. В коммерческих системах связи, где ценится натуральность звучания речи, обычно применяют полувокодеры (гибридные вокодеры), сочетающие принципы непараметрического и параметрического методов кодирования. Иные области применения вокодеров – автоматизированная стенография, озвучивание текста, человеко-машинный диалог, биометрия (идентификация диктора) [3].
Знакомясь с современным состоянием вокодерных технологий по литературным источникам и ресурсам Internet [4-8], можно видеть, что помимо программных и программно-аппаратных разработок вокодеров для промышленного, военного и бытового применения, существует еще несколько интересных и перспективных направлений:
· программные вокодеры-игрушки;
· лекции и лабораторные работы для желающих ознакомиться с базовыми принципами вокодерных технологий.
Перспективность этих направлений, по нашему мнению, состоит в возможности их объединения с целью создания соответствующих практикумов. Элементы таких практикумов уже сегодня можно встретить на страницах Internet, однако эта информацию разрозненна, неполна, и изложена преимущественно на английском языке.
В данной лекции мы рассмотрим несколько простейших программных модулей для среды Matlab, позволяющих как бы «изнутри» взглянуть на базовые принципы и алгоритмы параметрического кодирования речевых сигналов.
Кратко о видах вокодеров
Первый вокодер, полосный, был предложен в 1939 году Гомером Дадли [9]. Анализатор и синтезатор этого вокодера содержали гребенки полосовых фильтров, с помощью которых осуществлялось моделирование резонансных свойств речевого тракта человека. С развитием средств цифровой вычислительной техники полосные вокодеры стало удобным реализовывать на базе алгоритма быстрого преобразования Фурье (БПФ). Впоследствии были разработаны иные типы цифровых вокодеров, моделирующих резонансные свойства речевого тракта – гомоморфные, с линейным предсказанием, формантные [10,11].
В 1966 Фланаганом и Голденом [12] предложен иной тип вокодеров - фазовые вокодеры, в которых речевой сигнал аппроксимируют суммой узкополосных процессов, представляемых в виде гармоник, модулированных по амплитуде и частоте. Таким образом, в фазовых вокодерах реализуется идея «разделения» временных и спектральных свойств сигнала: информация о временных свойствах сигнала содержится в модулирующих сигналах в виде переменной амплитуды и фазы, а информация о частотных свойствах содержится в модулируемых сигналах, генерируемых осцилляторами [13]. Фазовые вокодеры позволяют сравнительно легко реализовывать такие эффекты как изменение темпа или высоты речевого сигнала.
В речеэлементных вокодерах [10,11], в отличие от двух предыдущих групп вокодеров, на этапе анализа осуществляется распознавание звуков речи. Это наиболее сложный в техническом отношении тип вокодеров, поскольку одни и те же слова и звуки разными людьми произносятся по-разному. Вместе с тем, такие вокодеры весьма перспективны, позволяя, в принципе, автоматически преобразовывать речь в текст и наоборот, текст - в речь. Одна из наиболее глубоко проработанных технологий такого рода – технология Microsoft Agent [14], элементы которой знакомы практически всем пользователям среды Microsoft Office.
End
% ==== график АЧХ фильтра-резонатора =====
figure; imagesc(t,f,20*log10(Bamp2)), axis xy, colormap(jet);
xlabel('ВремЯ, с'); ylabel('Частота, Гц'); title('Спектрограмма-2');


а) б)
Рис.3. Исходный речевой сигнал и его спектрограмма
На рис.4 показан фрагмент исходного речевого сигнала – слово «измерение», а на рис.5 показаны оценки спектров мощности (разрешение по частоте близко 100 Гц) первого гласного звука «и» (рис.5.а) и согласного звука «з» (рис.5.б) этого слова.
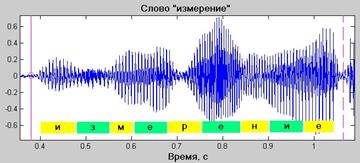
Рис.5. Осциллограмма слова «измерение»


а) б)
Рис.5. Спектры звуков «и» (а) и «з» (б) слова «измерение»
Гомоморфный вокодер.В гомоморфных вокодерах АЧХ фильтра-резонатора измеряют с помощью кепстрального анализа. В приведенном ниже примере речевой сигнал нарезается на сегменты протяженностью 512 выборок, перекрывающиеся на половину своей длины. По этим сегментам вычисляется спектрограмма с разрешением по частоте около 25 Гц и разрешением по времени 23.2 мс (рис.6.а).
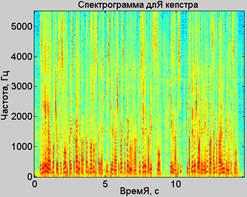

а) б)
Рис.6. Спектрограммы до (а) и после (б) вычисления кепстра
Столь высокое разрешение по частоте необходимо для сохранения информации о частоте основного тона. Далее для каждого из кратковременных спектров 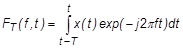 спектрограммы вычисляется кепстр:
спектрограммы вычисляется кепстр:
 , (1)
, (1)
где 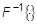 - символ обратного преобразования Фурье.
- символ обратного преобразования Фурье.
Поскольку информация о формантном составе речевого сигнала содержится в области малых значений 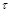 , оценку АЧХ фильтра получают в результате преобразования Фурье от кепстра, взвешенного окном
, оценку АЧХ фильтра получают в результате преобразования Фурье от кепстра, взвешенного окном 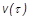 :
:
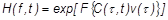 .
.
На рис.6.б приведена оценка АЧХ фильтра для треугольного окна с шириной основания 128 точек (11.6 мс при частоте дискретизации Fs=11025 Гц).
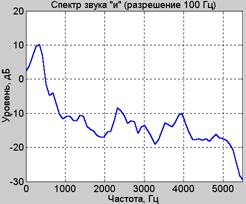
Чтобы лучше рассмотреть отличие приведенных на рис.6 спектрограмм, приведем их спектральные сечения, соответствующие гласному звуку «и»: на рис.7.а приведен спектр с разрешением 25 Гц, а на рис.7.б – с разрешением 100 Гц.

а) б)
Рис.7. Спектры звука «и» с разрешением 25 Гц (а) и 100 Гц (б)
В оценке спектра с более высоким разрешением отчетливо просматривается «тонкая» структура спектра, содержащая информацию о частоте основного тона.
Листинг программного модуля имеет вид:
% ============ analys_hmrf.m ===========
% Гомоморфный вокодер - анализ АЧХ голосового тракта
% x - анализируемый (речевой) сигнал
% ====================================
% === задание параметров ====
nfft = 512; fs = 11025;
tau=nfft/4+1; % ширина окна wincpstr, умножаемого на кепстр
% ======= Вычисление кепстра =====
window = rectwin(nfft); numoverlap = 256; % сегменты из 512, перекрываются на 256
[Bt,ft,tt] = specgram(x,nfft,fs,window,numoverlap);
%
figure; imagesc(tt,ft,20*log10(abs(Bt))), axis xy, colormap(jet); % график спектрограммы
xlabel('ВремЯ, с'); ylabel('Частота, Гц'); title('Спектрограмма длЯ кепстра');
%
Btamp = abs(Bt);
Bts=Btamp(2:end-1,:);
Btsi=flipud(Bts);
Btsim=[Btamp; Btsi];
Btsim=Btsim+10^(-3);
Bcpstr = real(ifft(log(Btsim))); % кепстр
%
% ====== Вычисление АЧХ речевой системы =========
wincps=zeros(129,1);
wincp=bartlett(tau); % кепстральное окно
for iwin=1:tau
wincps(iwin)=wincp(iwin);
End
wincpstr=circshift(wincps,-(tau-1)/2); % сдвиг кепстрального окна
wincpstr(65)=[]; % убираем лишний отсчет
Bcut=Bcpstr;
Bcut(65:448,:)=[]; % вычеркивание ненужных строк кепстра
for icut2=1:length(Bcut(1,:))
for icut1=1:128
Bcutwin(icut1,icut2)=Bcut(icut1,icut2).*wincpstr(icut1); % умнож. кепстра на окно
End
End
Pcutlog=real(fft(Bcutwin));
Pcut=exp(Pcutlog);
Bamp2=Pcut;
Bamp2(66:end,:)=[]; % АЧХ голосового тракта
fh=0:4*(ft(2)-ft(1)):ft(end);
figure; imagesc(tt,fh,20*log10(Bamp2)), axis xy, colormap(jet);xlabel('ВремЯ, с');
ylabel('Частота, Гц'); title('Спектрограмма из кепстра');
Вокодер с линейным предсказанием (липредер).В анализаторе вокодера с линейным предсказанием измеряют коэффициенты нерекурсивного «выбеливающего» фильтра. В синтезаторе такого вокодера применяют рекурсивный фильтр, обратный «выбеливающему».
Задача определения коэффициентов фильтра, входящего в состав синтезатора вокодера, аналогична задаче параметрического оценивания спектра мощности случайного процесса. Ее решение сводится к составлению и решению уравнений Юла-Уолкера [3]:
 , (2)
, (2)
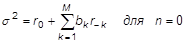 , (3)
, (3)
где  - отсчеты оценки корреляционной функции сегмента речевого сигнала,
- отсчеты оценки корреляционной функции сегмента речевого сигнала,  - оценка дисперсии белого шума, воздействующего на рассчитываемый фильтр.
- оценка дисперсии белого шума, воздействующего на рассчитываемый фильтр.
Найденные в результате решения системы уравнений (2)-(3) коэффициенты  и
и  - это коэффициенты рекурсивного фильтра, описываемого уравнением
- это коэффициенты рекурсивного фильтра, описываемого уравнением
 ,
,
с передаточной характеристикой
 ,
,
где  - воздействие на фильтр в виде дискретного белого шума единичной дисперсии;
- воздействие на фильтр в виде дискретного белого шума единичной дисперсии;  - отклик фильтра.
- отклик фильтра.
В приводимом ниже листинге программы вычисления АЧХ фильтра-резонатора речевой сигнал нарезается на неперекрывающиеся сегменты длиной 256 выборок (23.2 мс при частоте дискретизации Fs=11025 Гц).
% ============= analiz_lipreder.m ===================
%== вокодер с линейным предсказанием - анализаторнаЯ часть ===
% x - речевой (анализируемый) сигнал
% nseg - кол-во отсчетов в сегменте
% sdvig - величина сдвига сегментов
% b - коэффициенты полюсного фильтра
% sigma - СКО речевого сигнала
% ==================================================
fs=11025; % частота дискретизации
nseg=256; % кол-во отсчетов в сегменте
por_fil = 15; % порЯдок фильтра
sdvig=nseg; % сдвиг сегментов
b=[];
sigma=[];
for i= 1:sdvig:(length(x)-nseg) % начальные номера сегментов (перекрытие 0%)
for j=1:nseg
xseg(j)=x(i+j-1); % формирование i-того сегмента
end;
[Kxseg,lags] = xcov(xseg,por_fil,'biased'); % коррел.функц.сегмента
Kxseg_=Kxseg; Kxseg_(1:por_fil)=[]; % отбрас.отрицат.задержки корр.ф-ции
Kxseg_(por_fil+1)=[]; % отбрас.последнего отсчета корр.ф-ции
Kxtep=toeplitz(Kxseg_); % формирование матрицы Теплица
Kxseg(1:(por_fil+1))=[]; % отсчеты корр.ф-ции длЯ положит.задержек
%====== расчет коэффициентов фильтра =======
b_seg=-Kxtep\Kxseg'; % решение матричного уравнен. - (nseg/2+1) коэффициентов фильтра
%====== расчет СКО =======
sig_seg=sqrt(Kxseg_(1)+sum(b_seg.*Kxseg'));
%====== матрица b и массив sigma ===========
b=[b b_seg]; % объединение результир.сегментов
sigma=[sigma sig_seg];
end;
% конец вычислений
% ===== график СКО ======
figure;plot(sigma)
title('Сигма речевого сигнала (липредер)');
it= 1/fs:sdvig/fs:(length(x)-nseg)/fs;
jb=1:por_fil;
% ====== график коэф-в b =======
figure; imagesc(it,jb,b), axis xy, colormap(jet);
xlabel('ВремЯ, с'); ylabel('Номера коэфф-та bk'); title('Коэффициенты фильтра липредера');
% ===== график АЧХ =====
nfft = 128; fs = 11025;
window = rectwin(nfft); numoverlap = 0;
[B,f,t] = specgram(x,nfft,fs,window,numoverlap);
Bamp2=[];
for ib= 1:size(b,2) % начальные номера сегментов (перекрытие 50%)
bk1=b(:,ib);bks1=[1 bk1']; % полный вектор коэффициентов
sig=sigma(ib);
[Bamp2_seg,Bf]=freqz(sig,bks1,65);
Bamp2=[Bamp2 Bamp2_seg];
End
Bamp2=abs(Bamp2);
% график АЧХ голосового тракта
figure; imagesc(t,f,20*log10(Bamp2)), axis xy, colormap(jet);
xlabel('ВремЯ, с'); ylabel('Частота, Гц'); title('АЧХ липредера');
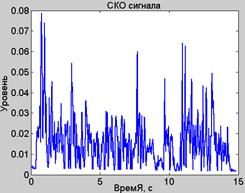
На рис.8 приведены примеры результатов вычислений значений и как функций времени, а на рис.9 – пример результат вычисления АЧХ фильтра-резонатора с переменными параметрами.
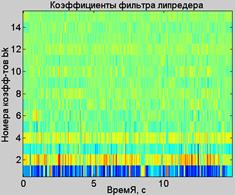
а) б)
Рис.8. СКО речевого сигнала (а) и коэффициенты фильтра липредера (б)

Рис.9. АЧХ фильтра липредера
На рис.10 показана форма АЧХ фильтра липредера для звуков «и» и «з» слова «измерение».
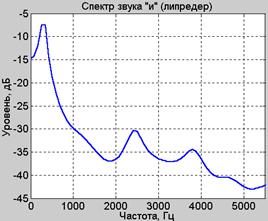

а) б)
Рис.10. АЧХ фильтра липредера для звуков «и» (а) и «з» (б)
Значительно более гладкая форма кривых на рис.10, по сравнению с рис.5 и рис.7, обусловлена невысоким порядком фильтра – в данном случае он равен 15.
Else
seg_clip(jc)=0;
End
End
sig_clip=[sig_clip seg_clip']; % sig_clip - результат клиппированиЯ сигнала
End
% ====== Вычисление АКФ клиппированного сигнала ========
akf_clip=[]; % АКФ клиппированного сигнала
for ic = 1:size(sig2dim,2)
[akf_seg_clip,tau_clip]=xcov(sig_clip(:,ic),'coeff');
akf_clip=[akf_clip akf_seg_clip];
End
% ====== Вычисление частоты основного тона ========
akf_inf=akf_clip(nfft+38:nfft+130,:); % выделение информативного участка АКФ
[akf_infm,indmx]=max(akf_inf);
for ic=1:length(akf_infm)
if akf_infm(ic)<0.2
Ton(ic)=0;
Else
Ton(ic)=fs/(indmx(ic)+37);
End
End
tTon=0:step/fs:(length(x)-nfft)/fs;
figure; plot(tTon,Ton) % график частоты основного тона
title('Частота основного тона (коррел.метод)');
Grid on
Кепстральный метод.Принципиальное отличие данного метода от корреляционного в том, что вместо оценки АКФ центрально-клиппированного сегмента речи используют оценку кепстра (1). На рис.14 приведен результат измерения кепстра речевого сегмента протяженностью 512 выборок (звук «и», осциллограмма которого приведена на рис.11.а). На приведенном графике отчетливо наблюдается всплеск бокового лепестка кепстра, соответствующий периоду основного тона примерно 8 мс (частота 125 Гц). Результат измерений частоты основного тона кепстральным методом приведен на рис.15
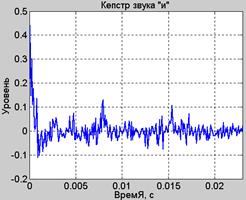

Рис.14. Кепстр звука «и» Рис.15. Частота основного тона
Листинг программы вычисления частоты основного тона по результатам кепстрального анализа имеет следующий вид:
% ============ main_tone_cpstr.m ===========
% Измерение частоты основного тона кепстральным методом
% Bcpstr - двумерный массив кепстров
% porog - порог обнаружениЯ кепстрального пика
% Ton - массив значений частоты тона (0 - признак шума)
% ====================================
porog=0.09; % порог обнаружениЯ кепстрального пика
% ====== Вычисление частоты основного тона ========
Cs=Bcpstr(38:130,:); % выделение информативного участка кепстра
for iz=1:93
for jz=1:length(Cs(1,:))
if Cs(iz,jz)<=0
Cs(iz,jz)=0; % отбрасывание отрицательных значений кепстра
End
End
End
% построение графика кепстра
[X,Y] = meshgrid(0:256/fs:256*(length(Cs(1,:))-1)/fs,38/fs:1/fs:130/fs);
figure;meshc(X,Y,Cs);
axis([1 15 38/fs 130/fs -0.1 0.4])
xlabel('ВремЯ, с'); ylabel('ВремЯ кестра, с'); title('Кепстр');
%
SumCs=sum(Cs);
for ic=1:length(SumCs)
for jc=1:93
Csn(jc,ic)=Cs(jc,ic)/SumCs(ic);
End
End
%
Csnp=(Csn-porog).*floor((sign(Csn-porog)+1)/2);
% построение графика нормированного кепстра выше порога
figure;meshc(X,Y,Csnp);
axis([1 15 38/fs 130/fs -0.1 0.4])
xlabel('ВремЯ, с'); ylabel('ВремЯ кестра, с');
title('Нормированный кепстр выше порога');
%
[Csnpm,indmx]=max(Csnp);
for ic=1:length(SumCs)
if Csnpm(ic)==0
Ton(ic)=0;
Else
Ton(ic)=fs/(indmx(ic)+37);
End
End
for iton=1:length(Ton) % устранение ложных выбросов
if Ton(iton)>290
Ton(iton)=0;
End
End
Else
for in1=1:nseg
segvoz(in1)=sawtooth(2*pi*Ton(nomTon)*in1/fs,1/fs); % периодич.сигнал (пила)
end;
end;
n=[n segvoz]; % чередование шум-пила
end;
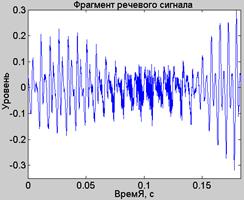
а) б)
Рис.18. Фрагменты речевого (а) и возбуждающего (б) сигналов
На рис.18 показаны фрагменты речевого и сгенерированного возбуждающего сигналов. Хотя в исходном речевом фрагменте (рис.18.а) единственный согласный звук окружен двумя гласными звуками, в сгенерированном возбуждающем сигнале (рис.18.б) наблюдается два шумовых участка, окруженных участками с пилообразным сигналом. Местоположение шумовых участков также не совсем точно совпадает с местоположением согласного звука. Это свидетельствует о не очень качественной работе алгоритма определения «гласный-согласный».
Литература
1. Скляр Б. Цифровая связь. – М., Вильямс, 2003. – 1099с.
2. Андреев И.В., Бабкин В.В., Знамеровский А.Е. Реализация многоканальных шлюзов IP-телефонии. – Труды 2-ой Международной конференции «Цифровая обработка сигналов и ее применение», 21-24 сентября 1999г., Москва, сс.432-435.
3. Применение цифровой обработки сигналов. Под ред.Э.Оппенгейма. – М., «Мир», 1980. – 550с.
4. Tan E. C. and Teo T. T. Real-Time Implementation of MELP Vocoder. - Journal of The Institution of Engineers, Singapore, Vol. 44, Issue 3, 2004, pp.38-58
5. Tarun Agarwal. Pre-Processing of Noisy Speech for Voice Coders. – A thesis submitted for the degree of Master of Engineering. – Department of Electrical & Computer Engineearing McGill University, Montreal, Canada,2002. – 80p.
6. http://www.sequencer.de/
7. http://www.analogx.com/
8. http://shay.ecn.purdue.edu/
9. Dudley, H., The Vocoder. Bell Labs Record, Vol.17, 1939, pp.122-126.
10. Рабинер Л.Р., Шафер Р.В. Цифровая обработка речевых сигналов. – М.,Радио и связь, 1981. – 494с.
11. Сапожков М.А., Михайлов В.Г. Вокодерная связь. – М.: Радио и связь, 1983. – 247 с.
12. J. L. Flanagan, R. M. Golden, "Phase Vocoder," Bell System Technical Journal, November 1966, 1493-1509.
13. Mark Dolson, "The phase vocoder: A tutorial," Computer Music Journal, vol. 10, no. 4, pp. 14 -- 27, 1986.
14. Буторин Д. MS Agent и Speech API в DELPHI. – С.-Пб, «БХВ-Петербург», 2005. – 431 с.
Введение
Вокодеры – это системы параметрического кодирования речи, широко применяемые в современной цифровой телефонной связи, в том числе – Internet-телефонии [1,2]. Причиной тому – высокая степень сжатия информации, а также хорошая согласованность вокодеров с системами канального кодирования и шифрования, в результате чего сравнительно легко обеспечивается высокая защищенность систем связи от помех и утечки информации. Недостатком вокодеров является невысокое качество речи, поэтому они применяются главным образом в военной связи, где главное – не натуральность речи, а ее высокая степень сжатия и хорошая разборчивость. В коммерческих системах связи, где ценится натуральность звучания речи, обычно применяют полувокодеры (гибридные вокодеры), сочетающие принципы непараметрического и параметрического методов кодирования. Иные области применения вокодеров – автоматизированная стенография, озвучивание текста, человеко-машинный диалог, биометрия (идентификация диктора) [3].
Знакомясь с современным состоянием вокодерных технологий по литературным источникам и ресурсам Internet [4-8], можно видеть, что помимо программных и программно-аппаратных разработок вокодеров для промышленного, военного и бытового применения, существует еще несколько интересных и перспективных направлений:
· программные вокодеры-игрушки;
· лекции и лабораторные работы для желающих ознакомиться с базовыми принципами вокодерных технологий.
Перспективность этих направлений, по нашему мнению, состоит в возможности их объединения с целью создания соответствующих практикумов. Элементы таких практикумов уже сегодня можно встретить на страницах Internet, однако эта информацию разрозненна, неполна, и изложена преимущественно на английском языке.
В данной лекции мы рассмотрим несколько простейших программных модулей для среды Matlab, позволяющих как бы «изнутри» взглянуть на базовые принципы и алгоритмы параметрического кодирования речевых сигналов.
Кратко о видах вокодеров
Первый вокодер, полосный, был предложен в 1939 году Гомером Дадли [9]. Анализатор и синтезатор этого вокодера содержали гребенки полосовых фильтров, с помощью которых осуществлялось моделирование резонансных свойств речевого тракта человека. С развитием средств цифровой вычислительной техники полосные вокодеры стало удобным реализовывать на базе алгоритма быстрого преобразования Фурье (БПФ). Впоследствии были разработаны иные типы цифровых вокодеров, моделирующих резонансные свойства речевого тракта – гомоморфные, с линейным предсказанием, формантные [10,11].
В 1966 Фланаганом и Голденом [12] предложен иной тип вокодеров - фазовые вокодеры, в которых речевой сигнал аппроксимируют суммой узкополосных процессов, представляемых в виде гармоник, модулированных по амплитуде и частоте. Таким образом, в фазовых вокодерах реализуется идея «разделения» временных и спектральных свойств сигнала: информация о временных свойствах сигнала содержится в модулирующих сигналах в виде переменной амплитуды и фазы, а информация о частотных свойствах содержится в модулируемых сигналах, генерируемых осцилляторами [13]. Фазовые вокодеры позволяют сравнительно легко реализовывать такие эффекты как изменение темпа или высоты речевого сигнала.
В речеэлементных вокодерах [10,11], в отличие от двух предыдущих групп вокодеров, на этапе анализа осуществляется распознавание звуков речи. Это наиболее сложный в техническом отношении тип вокодеров, поскольку одни и те же слова и звуки разными людьми произносятся по-разному. Вместе с тем, такие вокодеры весьма перспективны, позволяя, в принципе, автоматически преобразовывать речь в текст и наоборот, текст - в речь. Одна из наиболее глубоко проработанных технологий такого рода – технология Microsoft Agent [14], элементы которой знакомы практически всем пользователям среды Microsoft Office.
Вокодер как цифровая модель речевого тракта
Ядром вокодера, - цифровой модели речевого тракта, - является цифровой фильтр с переменными параметрами, АЧХ которого изменяется во времени, отражая изменение резонансных свойствах речевого тракта. В анализаторе вокодера измеряются характеристики этого фильтра, а в синтезаторе фильтр воссоздается по результатам этих измерений (рис.1).
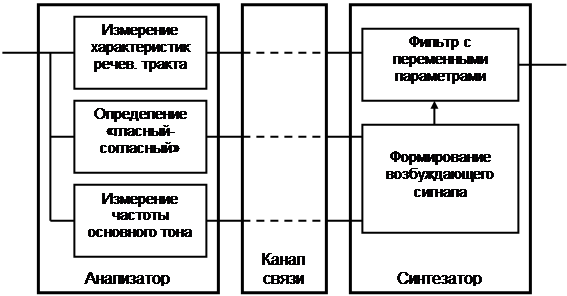 |
Рис.1. Обобщенная структурная схема полосного вокодера
 |  |
Рис.2. Структура программных модулей анализатора и синтезатора
Кроме того, в анализаторе определяется, какой звук имеет место в данный момент времени – гласный или согласный, а также измеряется частота основного тона гласного звука. В синтезаторе на основе этой информации формируется возбуждающий сигнал: для согласных звуков это шум, для гласных – периодическая последовательность импульсов с периодом, равным периоду основного тона. Структура программных модулей анализатора и синтезатора приведена на рис.2.
Подчеркнем, что решающую роль в разборчивости синтезированного речевого сигнала играет информация о резонансных свойствах речевого тракта. Так, возбуждая фильтр синтезатора только шумом либо только периодической последовательностью импульсов, можно получить вполне разборчивую речь. Отличие лишь в том, что в первом случае мы услышим шепот, во втором - «голос робота».
Последнее изменение этой страницы: 2016-08-28
lectmania.ru. Все права принадлежат авторам данных материалов. В случае нарушения авторского права напишите нам сюда...