Категории:
ДомЗдоровьеЗоологияИнформатикаИскусствоИскусствоКомпьютерыКулинарияМаркетингМатематикаМедицинаМенеджментОбразованиеПедагогикаПитомцыПрограммированиеПроизводствоПромышленностьПсихологияРазноеРелигияСоциологияСпортСтатистикаТранспортФизикаФилософияФинансыХимияХоббиЭкологияЭкономикаЭлектроника
Распознавание рукопечатных символов с использованием структурно-признакового анализа
Распознавание рукопечатных символов с использованием структурно-признакового анализа
А.Г. Вихров, к.т.н., доцент, Р.П. Богуш, к.т.н., доцент, Д.О. Глухов
УО «Полоцкий государственный университет», Новополоцк
Предложен алгоритм распознавания рукопечатных символов с использованием структурно-признакового метода, основанного на выделении дескрипторов формы. Алгоритм предполагает предварительную скелитизацию символа, разбиение области символа на блоки, описание символа с помощью дескрипторов и сравнения их с эталонными. В работе также представлены результаты исследований по оценке эффективности разработанного алгоритма, алгоритм позволяет распознавать рукопечатные символы с точностью, достигаемой 96%.К достоинству алгоритма следует также отнести небольшой набор эталонов, что способствует более высокому быстродействию, не ухудшая вероятность правильного распознавания. Таким образом, разработанный алгоритм может использоваться для повышения качества функционирования различных систем оффлайн распознавания, например, в банковских структурах при заполнении заявлений на оформление пластиковых карточек, прием платежей, денежные переводы и т.д.
Введение
Распознавание рукопечатных символов (написанных от руки печатными буквами) весьма актуально для различных видов современных наукоемких технологий, использующих процесс оптического ввода документов: автоматическая обработка платежных ведомостей в банках, результатов анкетирования или голосования, пенсионных форм и т.д. [1,2]. Причем область применения распознавания символов непрерывно расширяется [1]. Для решения такой задачи существует ряд алгоритмов и программных средств. Так, в работе [3] представлена программа распознавания рукописных прописных русских букв и цифр на основе метода сравнения с эталонными изображениями соответствующих символов. Однако, данный алгоритм обладает рядом существенных ограничений, поэтому для повышения точности распознавания отдельных символов необходимо выполнять горизонтальную и вертикальную проверку симметричности образа, наличия замкнутых областей (О, В, Д, Р и др.), количество отрезков и дуг, их взаимное расположение и ориентация (требуется векторизация изображения). В статье [4] рассматривается обработка рукопечатных символов, на основе распознавания их скелетного представления. Следует отметить, что приданном подходе повышение точности распознавания осуществляется за счет значительного увеличения временных затрат. Суть алгоритма, рассмотренного в [4] заключается в разбиении изображения на трапеции и выделении узловых областей. Недостатком алгоритма является то, что при таком подходе не учитываются некоторые особенности почерков. Кроме данных алгоритмов известны и другие методы распознавания печатного текста[5-8], которые удовлетворяют основным требованиям систем автоматизации документооборота. Однако, создание нового программного продукта в данной области по-прежнему остается актуальной задачей и требует разработки новых, более эффективных алгоритмов распознавания и проведения исследований в связи со специфическими требованиями по разрешению, быстродействию, надежности распознавания и объему памяти, которыми характеризуется каждая конкретная задача разработки проблемно-ориентированной системы автоматического ввода в компьютер бумажной документации.
Описание алгоритма распознавания
Разработанный алгоритм распознавания рукопечатных символов предполагает выполнение следующих этапов: фильтрация полутонового изображения; адаптивная бинаризация заданных областей; фильтрация бинарного изображения; сегментация слов; сегментация символов; скелетизация символов; описание символа с использованием дескрипторов формы; получение вектора дескрипторов и сравнение его с базой векторов.
Адаптивная бинаризация
При бинаризации изображения яркость каждого пикселя f(x,y) сравнивается с пороговым значением яркости T, если значение яркости пикселя выше значения яркости порога, то на бинарном изображении соответствующий пиксель будет «белым», или «черным» в противном случае [10]:
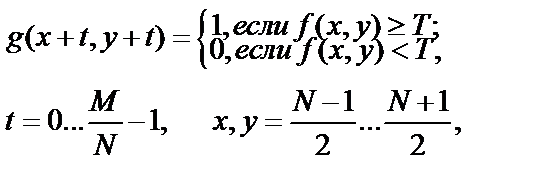
где N×N – размер области поиска порога;
T – порог бинаризации;
М×М – размер области изображения.
Адаптивная бинаризация используется при обработке полутоновых изображений невысокого качества, на которых из-за неравномерности фона обычная бинаризация дает плохие результаты. Функция сглаживания результирующего растра при адаптивной бинаризации позволяет получить удовлетворительный результат без использования дополнительных фильтров(см. рис.2).
При адаптивной бинаризации для каждого пикселя изображения f определяются [11]:
1. В окрестности пикселя, исходного изображения f выбирается область размерами N×N, где рассчитывается порог T. Причем порог рассчитывается по формуле:
 , (5)
, (5)
где Т – порог бинаризации определенный в локальной области; min – минимальное значение яркости; max – максимальное значение яркости.
2. Если f(x,y) >T, результат 1, иначе 0.
 а)
а)
|  б)
б)
|
Рис. 2.Результат выполнения адаптивной бинаризации: а) исходное изображение; б) результат бинаризации
Сегментация слов
Исходными данными для алгоритма сегментации слов служит изображение одной текстовой строки, которое получается из исходного изображения документа (см. рис.4).

Рис. 4. Результат сегментации слова
Для сегментации слов необходимо выделить абсолютные пределы слова на общем растре изображения, используя условия:
 ,
,
где f – выделенная строковая область; hin – ордината верхнего угла; hik – ордината нижнего угла; win – абсцисса крайнего левого положения слова; wik – абсцисса крайнего правого положения слова; t – диапазон, на котором определяется наличие черных пикселей; N– ширина области сегментации; М – высота области сегментации.
Алгоритм сегментации слов основывается на том, что средняя яркость в интервалах между словами  ниже диапазона средней яркости в изображениях слов
ниже диапазона средней яркости в изображениях слов  . Для всех пиксельных столбцов исходного изображения строки необходимо найти их средние значения яркости и определить среднее значение яркости для данного изображения строки:
. Для всех пиксельных столбцов исходного изображения строки необходимо найти их средние значения яркости и определить среднее значение яркости для данного изображения строки:
 ,
,
где f – область «черных» пикселей; g – область «белых» пикселей; k – количество пикселей в областях.
Работа алгоритма сегментации слов заключается в последовательном анализе множества средних значений яркости столбцов (y1,…,yn) и выявлении множества пар индексов (yli,yri) пиксельных строк, соответствующих левой yli и правой yri границам изображения слова номер i.Средняя яркость в интервалах между словами должна быть невелика (в идеальном случае она равна нулю). Поэтому ее левую границу (начало слова) можно выразить через среднюю яркость изображения строки.
Ключевым звеном сегментации слов является выделение пробела (см. рис.5). Пробел между словами может быть определен по расстоянию между соседними символами по формуле:
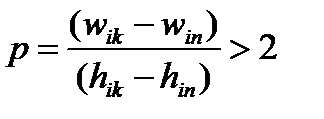 ,
,
где р – признак выделенного пробела.

Рис. 4. Результат сегментации пробела
Сегментация символов
В большинстве изображений слов символы расположены близко друг к другу и межсимвольные интервалы не так ярко выражены, как в случае межстрочных интервалов ли интервалов между словами. Исходными данными для алгоритма сегментации символов служит изображение области слова, которое получается из изображения текстовой строки после применения к нему алгоритма сегментации слов.
Алгоритм сегментации символов основывается на том, что средняя яркость в межсимвольных интервалах , по крайней мере, ниже средней яркости в изображениях символов  .Поставленная задача решается путем последовательного горизонтального, а затем вертикального применения масокдля заданной области. При горизонтальной и вертикальной обработке символа необходимо руководствоваться направленной связностью областей символа, определяемой масками W1–W8 (см. рис.5.).
.Поставленная задача решается путем последовательного горизонтального, а затем вертикального применения масокдля заданной области. При горизонтальной и вертикальной обработке символа необходимо руководствоваться направленной связностью областей символа, определяемой масками W1–W8 (см. рис.5.).

| 
| 
| 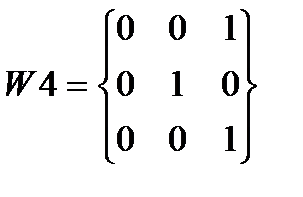
|
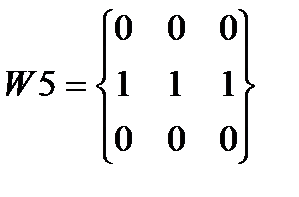
| 
| 
| 
|
Рис. 5.. Направленные маски, используемые для определения связности областей сегментированного символа
При сегментации символов, учитывается пропорциональность символа, т.е. отношение p высоты hsym символа к ширине wsym определяется как:
 .
.
Результат сегментации символов приведен на рисунке 6.

Рис. 6 Результат сегментации символов
Скелетизация
Процесс выделения скелета символа выполняется по следующим этапам:
1. Выделение контура символа таким образом, чтобы внутри этого контура находилось бы линия единичной толщины.
2. Пошаговое удаление внешнего контура.
3. Проведение последовательных этапов морфологической обработки: дилатации и эрозии. Дилатация позволит соединить разрывы, которые образовались на этапе 2. Эрозия приведет к утоньшению.
4. Фильтрация полученного скелета символа от шумов, которые могут возникнуть на этапе 3.
Чтобы выделить контур символа необходимо воспользоваться правилом «жука» [12].Математически движение жука можно представить в виде системы уравнений:
 ,
,
где g – массив выделенного контура, полученный методом жука, f – входной сигнал символа.
Далее выполняется масочная фильтрация (маски показаны на рис.7) скелетизированного символа для поиска отдельных несвязных областей (см. рисунок 14).
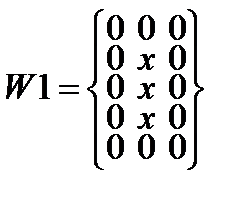
| 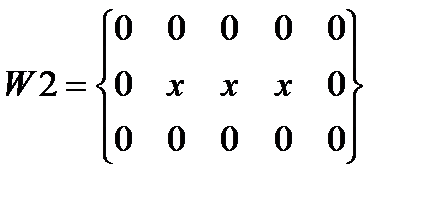
| 
|
где x – элемент бинарного изображения.
Рис. 7.Маски, используемые при фильтрации скелетизированного символа
Замыкание представляет собой последовательно выполненные две морфологические операции дилатацию и эрозию[9]:
B • S = ( B ⊕ S )ΘS,
где S – структурирующий элемент типа «квадрат» размерами 3х3; B – входящее изображение.
В результате скелетизации и фильтрации символа, а затем последовательного применения дилатации и эрозии обеспечивается удовлетворительная скелетизация и заполнение разрывов исходного символа (рис.8).




а) б) в) г)
Рис. 8.Примеры результатов поэтапной скелетизации символа: а) результат выделения контура символа; б) результат получения скелета символа путем двойного вычитания контура символа; в) результат фильтрации полученного скелета; г) результат размыкания символа, окончательный скелет символа
Заключение
Разработка новых программных продуктов для оптического ввода документов в настоящее время является актуальной задачей, решение которой требует разработки новых, более эффективных алгоритмов распознавания рукопечатных и рукописных символов в связи со специфическими требованиями по быстродействию, надежности распознавания и другими требованиями, которыми характеризуется каждая конкретная задача разработки проблемно-ориентированной системы автоматического ввода в компьютер бумажной документации.
Проведенный анализ существующих методов показал, что одним из эффективных методов распознавания является метод, использующий структурно-признаковый анализ. На базе данного метода разработан алгоритм распознавания рукопечатных символов, основными этапами которого являются фильтрация полутонового изображения, адаптивная бинаризация заданных областей, фильтрация бинарного изображения, сегментация слов, сегментация символов, скелетизация символов, описание символа с использованием дескрипторов формы, получение вектора дескрипторов и сравнение его с базой. Разработан набор признаков и их геометрическое взаимодействие между собой, по которым происходит сравнение текущего символа с эталонными. Проведены экспериментальные исследования и установлено, что созданный алгоритм позволяет распознавать символы с достаточно высокой точностью, достигаемой 96 процентов для букв русского алфавита..
Символы у которых дескрипторы семейства К, ППС и ПВС имеют несколько схожих эталонов разных групп символов имеют процент ошибочного распознавания. К таким символам относятся «Н», «З», «Э», «А», «Д», «Я». Максимальный процент распознавания у тех символов, которые имеют группу эталонов на один символ. Примером таких символов являются «Ж», «Р», «И», «Ю», «М», «Ч».
Литература
1. Системы оптического распознавания документов[Электронный ресурс]/ Прохоров А. Режим доступа – http://www.compress.ru/article.aspx?id=11745&iid=458 – Дата доступа: 19.04.10.
2. Дробков, А.В., Семенов, А.Б. (2009) Исследование одного метода распознавания рукопечатных символов. Вестник ТвГУ. Серия: Прикладная математика (15). Стр. 15-26
3. Реализация алгоритма распознавания графических образов. [Электронный ресурс]/ Ю. Кисляков. Режим доступа – http://www.citforum.ru. – Дата доступа: 03.02.06
4. Распознавание скелетных образов. [Электронный ресурс]/ Н.В. Котович, О.А. Славин. Режим доступа – http://www.octavi.narod.ru. – Дата доступа: 01.04.03
5. Эффективный алгоритм предобработки изображений для структурных методов распознавания рукописных символов. [Электронный ресурс]/Р.В. Поцепаев, И.Б. Петров. Режим доступа – http://www.zhurnal.ape.relarn.ru. – Дата доступа: 01.01.03
6. О.К. Нусратов, П.Ш. Гейдаров Метод распознавания рукопечатных символов и текстов. [Электронный ресурс]/ Режим доступа – www.science.az/cyber/pci2006/5/!5r01-nusratov.doc. – Дата доступа: 06.03.10
7. Патент Российской Федерации 2309456, МПК G06K9/36 , опубл. 27.10.2007
8. Патент Российской Федерации 2295154, МПК G06K9/68, опубл. 10.03.2007
9. Цифровая обработка изображений/Р. Гонсалес, Р. Вудс. – Москва: Техносфера, 2005. – 1072с
10. Бинаризация черно-белых изображений: состояние и перспективы развития [Электронный ресурс]/ А. Федоров. Режим доступа – http://www.philippovich.ru/Library/Books/ITS/wwwbook/ist4b/its4/fyodorov.htm. – Дата доступа: 01.04.03
11. Обработка и распознавание изображений в системах превентивной безопасности: Учебное пособие. Режим доступа – http://window.edu.ru. – Дата доступа: 27.08.09.
12. Структурный анализ цифровых контуров изображений как последовательностей отрезков прямых и дуг кривых/ В.В. Вишневский, В.Г. Калмыков. Режим доступа – http://www.iai.dn.ua. – Дата доступа: 05.09.09.
Распознавание рукопечатных символов с использованием структурно-признакового анализа
Последнее изменение этой страницы: 2016-07-22
lectmania.ru. Все права принадлежат авторам данных материалов. В случае нарушения авторского права напишите нам сюда...