Категории:
ДомЗдоровьеЗоологияИнформатикаИскусствоИскусствоКомпьютерыКулинарияМаркетингМатематикаМедицинаМенеджментОбразованиеПедагогикаПитомцыПрограммированиеПроизводствоПромышленностьПсихологияРазноеРелигияСоциологияСпортСтатистикаТранспортФизикаФилософияФинансыХимияХоббиЭкологияЭкономикаЭлектроника
Фильтрация полутонового изображения
Первым этапом обработки изображений является уменьшение шумов входного изображения  для повышения качества распознавания символов [9].Для обработки полутоновых изображений традиционно используется масочная фильтрация. При обработке изображений используется декартова система координат с началом в левом верхнем углу области и с положительными направлениями из этой точки вправо и вниз. В данном алгоритме используется максимальная фильтрация с апертурой, имеющей центральную симметрию, при этом ее центр располагается в текущей точке фильтрации. Формальное обозначение описанной процедуры представляется в виде:
для повышения качества распознавания символов [9].Для обработки полутоновых изображений традиционно используется масочная фильтрация. При обработке изображений используется декартова система координат с началом в левом верхнем углу области и с положительными направлениями из этой точки вправо и вниз. В данном алгоритме используется максимальная фильтрация с апертурой, имеющей центральную симметрию, при этом ее центр располагается в текущей точке фильтрации. Формальное обозначение описанной процедуры представляется в виде:
 ,
,
где N×N – размер области поиска максимума;
f – исходное изображение;
g – полученное изображение.
На рис. 1 показан пример выполнения максимальной фильтрации символа.
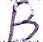 а)
а)
|  б)
б)
|
Рис. 1. Выполнение фильтрации полутонового изображения: а) исходное изображение; б) результат фильтрации
Адаптивная бинаризация
При бинаризации изображения яркость каждого пикселя f(x,y) сравнивается с пороговым значением яркости T, если значение яркости пикселя выше значения яркости порога, то на бинарном изображении соответствующий пиксель будет «белым», или «черным» в противном случае [10]:
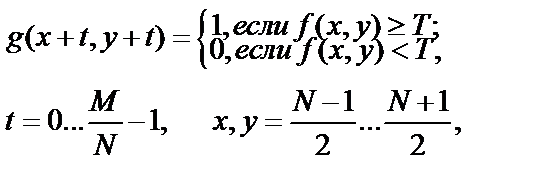
где N×N – размер области поиска порога;
T – порог бинаризации;
М×М – размер области изображения.
Адаптивная бинаризация используется при обработке полутоновых изображений невысокого качества, на которых из-за неравномерности фона обычная бинаризация дает плохие результаты. Функция сглаживания результирующего растра при адаптивной бинаризации позволяет получить удовлетворительный результат без использования дополнительных фильтров(см. рис.2).
При адаптивной бинаризации для каждого пикселя изображения f определяются [11]:
1. В окрестности пикселя, исходного изображения f выбирается область размерами N×N, где рассчитывается порог T. Причем порог рассчитывается по формуле:
 , (5)
, (5)
где Т – порог бинаризации определенный в локальной области; min – минимальное значение яркости; max – максимальное значение яркости.
2. Если f(x,y) >T, результат 1, иначе 0.
|
а)
|  б)
б)
|
Рис. 2.Результат выполнения адаптивной бинаризации: а) исходное изображение; б) результат бинаризации
Фильтрация бинарного изображения
Суть алгоритма фильтрации бинарного изображения заключается в использовании области размерами N×N в окрестности точки с координатами (x,y), где находится количество белых пикселей [9]. Применение этого фильтра приводит к уменьшению шума, так как количество белых пикселей сравнивается с некоторым порогом Т.
 ,
,
где f – исходное изображение; g – полученное изображение;f1(x,y) – пиксель изображения, соответствующий белому цвету.
Величина порога Т естественным образом влияет на результат обработки. Однако, варьируя значение порога, можно усилить подавление отдельных шумов на изображении и ослабить подавление других. Пример применения логической фильтрации приведен на рисунке 3.
|
а)
|  б)
б)
|
Рис. 3. Применение фильтрации бинарного изображения:а) исходное изображение; б) результат фильтрации
Сегментация слов
Исходными данными для алгоритма сегментации слов служит изображение одной текстовой строки, которое получается из исходного изображения документа (см. рис.4).

Рис. 4. Результат сегментации слова
Для сегментации слов необходимо выделить абсолютные пределы слова на общем растре изображения, используя условия:
 ,
,
где f – выделенная строковая область; hin – ордината верхнего угла; hik – ордината нижнего угла; win – абсцисса крайнего левого положения слова; wik – абсцисса крайнего правого положения слова; t – диапазон, на котором определяется наличие черных пикселей; N– ширина области сегментации; М – высота области сегментации.
Алгоритм сегментации слов основывается на том, что средняя яркость в интервалах между словами  ниже диапазона средней яркости в изображениях слов
ниже диапазона средней яркости в изображениях слов  . Для всех пиксельных столбцов исходного изображения строки необходимо найти их средние значения яркости и определить среднее значение яркости для данного изображения строки:
. Для всех пиксельных столбцов исходного изображения строки необходимо найти их средние значения яркости и определить среднее значение яркости для данного изображения строки:
 ,
,
где f – область «черных» пикселей; g – область «белых» пикселей; k – количество пикселей в областях.
Работа алгоритма сегментации слов заключается в последовательном анализе множества средних значений яркости столбцов (y1,…,yn) и выявлении множества пар индексов (yli,yri) пиксельных строк, соответствующих левой yli и правой yri границам изображения слова номер i.Средняя яркость в интервалах между словами должна быть невелика (в идеальном случае она равна нулю). Поэтому ее левую границу (начало слова) можно выразить через среднюю яркость изображения строки.
Ключевым звеном сегментации слов является выделение пробела (см. рис.5). Пробел между словами может быть определен по расстоянию между соседними символами по формуле:
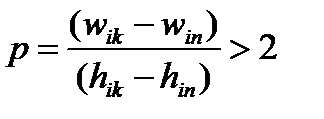 ,
,
где р – признак выделенного пробела.

Рис. 4. Результат сегментации пробела
Сегментация символов
В большинстве изображений слов символы расположены близко друг к другу и межсимвольные интервалы не так ярко выражены, как в случае межстрочных интервалов ли интервалов между словами. Исходными данными для алгоритма сегментации символов служит изображение области слова, которое получается из изображения текстовой строки после применения к нему алгоритма сегментации слов.
Алгоритм сегментации символов основывается на том, что средняя яркость в межсимвольных интервалах , по крайней мере, ниже средней яркости в изображениях символов  .Поставленная задача решается путем последовательного горизонтального, а затем вертикального применения масокдля заданной области. При горизонтальной и вертикальной обработке символа необходимо руководствоваться направленной связностью областей символа, определяемой масками W1–W8 (см. рис.5.).
.Поставленная задача решается путем последовательного горизонтального, а затем вертикального применения масокдля заданной области. При горизонтальной и вертикальной обработке символа необходимо руководствоваться направленной связностью областей символа, определяемой масками W1–W8 (см. рис.5.).

| 
| 
| 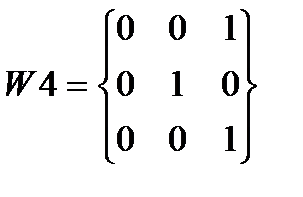
|
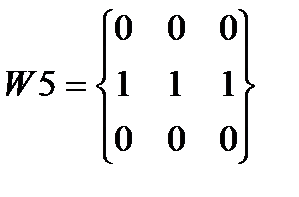
| 
| 
| 
|
Рис. 5.. Направленные маски, используемые для определения связности областей сегментированного символа
При сегментации символов, учитывается пропорциональность символа, т.е. отношение p высоты hsym символа к ширине wsym определяется как:
 .
.
Результат сегментации символов приведен на рисунке 6.

Рис. 6 Результат сегментации символов
Скелетизация
Процесс выделения скелета символа выполняется по следующим этапам:
1. Выделение контура символа таким образом, чтобы внутри этого контура находилось бы линия единичной толщины.
2. Пошаговое удаление внешнего контура.
3. Проведение последовательных этапов морфологической обработки: дилатации и эрозии. Дилатация позволит соединить разрывы, которые образовались на этапе 2. Эрозия приведет к утоньшению.
4. Фильтрация полученного скелета символа от шумов, которые могут возникнуть на этапе 3.
Чтобы выделить контур символа необходимо воспользоваться правилом «жука» [12].Математически движение жука можно представить в виде системы уравнений:
 ,
,
где g – массив выделенного контура, полученный методом жука, f – входной сигнал символа.
Далее выполняется масочная фильтрация (маски показаны на рис.7) скелетизированного символа для поиска отдельных несвязных областей (см. рисунок 14).
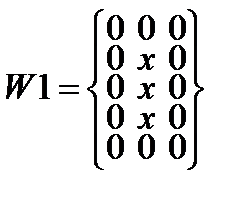
| 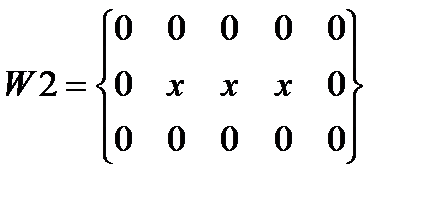
| 
|
где x – элемент бинарного изображения.
Рис. 7.Маски, используемые при фильтрации скелетизированного символа
Замыкание представляет собой последовательно выполненные две морфологические операции дилатацию и эрозию[9]:
B • S = ( B ⊕ S )ΘS,
где S – структурирующий элемент типа «квадрат» размерами 3х3; B – входящее изображение.
В результате скелетизации и фильтрации символа, а затем последовательного применения дилатации и эрозии обеспечивается удовлетворительная скелетизация и заполнение разрывов исходного символа (рис.8).




а) б) в) г)
Рис. 8.Примеры результатов поэтапной скелетизации символа: а) результат выделения контура символа; б) результат получения скелета символа путем двойного вычитания контура символа; в) результат фильтрации полученного скелета; г) результат размыкания символа, окончательный скелет символа
Последнее изменение этой страницы: 2016-07-22
lectmania.ru. Все права принадлежат авторам данных материалов. В случае нарушения авторского права напишите нам сюда...