Категории:
ДомЗдоровьеЗоологияИнформатикаИскусствоИскусствоКомпьютерыКулинарияМаркетингМатематикаМедицинаМенеджментОбразованиеПедагогикаПитомцыПрограммированиеПроизводствоПромышленностьПсихологияРазноеРелигияСоциологияСпортСтатистикаТранспортФизикаФилософияФинансыХимияХоббиЭкологияЭкономикаЭлектроника
Структура математического обеспечения ЭВМ
Структура математического обеспечения ЭВМ
СМО
 |  |
 Системное-программное Прикладное программное обеспечение обеспечение
Системное-программное Прикладное программное обеспечение обеспечение

 (операционные системы)
(операционные системы)
 |  |
Средства Средства Программы Программы
програм-мирования
управления
пользователя
технического обслуживания (тесты)
Средства программирования
Существуют такие средства программирования:
Текстовые редакторы (диалоговые программы);
Трансляторы (перевод с одного языка на другой, чаще из алгоритмического языка на язык программных кодов), препроцессор, интерпретатор, компилятор - перекладывают с одного языка высокого уровня на другой;
Редакторы связей (компоновщики) lіnker;
Утилиты (сервисные программы, копирование, перемещение и т.д.);
Средства управления
Средствами управления являются:
−Внутренние команды (при изготовлении ПК);
−Внешние программы (в DOS);
−Драйверы (программы, которые руководят внешними устройствами).
Элементы компиляции. Анализ формальных языков
Сведения о регулярных выражениях и грамматиках
Любой язык имеет свой алфавит.
Алфавит – это конечное множество I элементов, называемых символами.
Цепочка или слово в алфавите I – это конечная последовательность элементов (символов) из алфавита I. Например, если алфавит языка состоит только из заглавных и строчных букв латинского алфавита, то любые последовательности этих букв являются цепочками (словами), в том числе цепочка может состоять из одного символа.
С цепочками (словами) могут быть проделаны действия, которые имеют следующие обозначения:
§ хn. Цепочка символов х повторяется (пишется без пробелов одна за другой) n раз. Например, abba2 – это abbaabba.
§ хk. Цепочка символов х записывается в обратной последовательности. Например, portR - это trop.
§ xy. За цепочкой символов x без пробела помещается цепочка символов y.
§ х*. Цепочка символов х в цикле может повторяться нуль и более раз.
Обычно в алгоритмических языках a это действие реализуется циклом с предварительной проверкой условия.
Например: intl iden (‘,’ iden)* ‘;’
Это означает, что за символом intl должно следовать iden. Затем через запятую может еще повторяться iden нуль и более раз. В конце должна быть точка с запятой.
· х+. Цепочка символов х должна повторяться один и больше раз. В алгоритмическом языке Pascal это реализуется оператором repeat, а в языке Си – оператором цикла do while.
· |х|. Определение длины цепочки символов х (количество символов в цепочке).
· {} или l, или e - обозначение пустой цепочки символов.
· [х]. Так обозначается необязательная цепочка символов. Например, такая запись нужна для того, чтобы обозначить, что перед числом знак может быть, а может и отсутствовать.
Кроме алфавита и цепочки символов (слов), важным понятием является язык.
Язык в алфавите I – это произвольное множество цепочек (слов).
Регулярные выражения
Это цепочки символов, в которые входят не только символы из некоторого алфавита I, но и другие символы, которые часто носят служебный характер. Например, это могут быть запятая для разделения других символов, а также символы для обозначения каких-либо действий над цепочками. Пусть множество {,* |} из перечисленных в фигурных скобках символов не входит в алфавит I. Тогда цепочка символов из объединения IU{,* |} называется регулярным выражением. Эти выражения обычно используются для описания синтаксиса какого-либо алгоритмического языка.
Грамматика
Грамматика G=(T,N,P,S),
где T - алфавит т.н. терминальных символов. Это символы, которые заведомо определены. Например, это символы, используемые в каком-либо алгоритмическом языке. Какие это символы и какое их качество – все это заведомо определено. Только эти символы в дальнейшем используются при написании программ на этом алгоритмическом языке.
N – алфавит т.н. нетерминальных символов. Это символы, которые обычно используются для определения каких-либо понятий. Такими понятиями в алгоритмическом языке, например, являются идентификатор, переменная, константа, выражение, оператор и, в конце концов, программа. Обычно эти понятия перечисляются и обозначаются символами. Эти символы определяются через терминальные символы или, кроме того, через другие нетерминальные символы более низкого уровня. Например, при определении нетерминального символа “программа” используются терминальные символы алгоритмического языка, а также нетерминальные символы “оператор”, “выражение”, “слагаемое” и др.
Множества T и N не пересекаются. Обычно терминальные символы обозначаются строчными буквами, а нетерминальные – заглавными. Р – множество правил вывода для нетерминальных символов. Например, это правила описания переменных, констант, написания выражений, операторов и т.д. S – стартовый (главный) нетерминальный символ. Для алгоритмических языков это обычно нетерминальный символ “программа”.
Формальное определение языка
Способы получения цепочек символов необходимы, чтобы формально дать определение языка L(G), описываемого заданной грамматикой G. Язык L(G) – это множество цепочек w терминальных (и только терминальных!) символов, выводимых из начального (стартового, главного) нетерминального символа S. L(G)={w|S Þ*w, где w – терминальные цепочки}.
Вертикальная черта после w в выражении означает, что w получены при условии, что они выводятся из S. А звездочка означает, что этот вывод может происходить за произвольное количество операций. При этом используется множество P правил, описанное в грамматике G.
Ниже приводятся примеры грамматики и описываемые ими языки.
Пример 1 G=(T,N,P,S).
T={x,y,w,z} – алфавит терминальных символов. Только эти символы можно использовать.
N={S,A,B} – множество нетерминальных символов, из которых S – главный (стартовый) нетерминальный символ. Именно с него должен начинаться вывод цепочек (слов) в соответствии с множеством правил вывода P.
Р={S®AB, A®x, A®y, B®w, B®z}.
Эти правила означают, что S можно заменить на последовательность нетерминальных символов AB. A®x, A® y означает, что А можно заменить на x или на y и т.д. Осуществляя эти замены, получаем цепочки w из терминальных символов, составляющих формальный язык L(G).
L(G)={xw, yw, xz, yz}.
Только эти четыре цепочки (слова) и составляют язык, описываемый заданной грамматикой G.
Расширенные грамматики
Существуют т.н. расширенные грамматики. Они порождают те же языки, что и рассмотренные выше грамматики, но являются более наглядными.
Расширенные грамматики задаются парами
Ai ® ri,
где Ai ЄN – i-й нетерминальный символ.
ri – i-е регулярное выражение в алфавите NUT.
Нетерминальный символ первой пары является ГЛАВНЫМ (стартовым)для вывода цепочек.
Например, расширенная грамматика, эквивалентная описанной в примере выше, имеет вид:
S®AB ,
A®x|y,
B®w|z.
Напомним, что вертикальная черта читается как “или”. То есть А может быть заменена на x или y, а В – на w или z.
Задачи анализа
Даны цепочка символов (слов) и грамматика. Нужно узнать, принадлежит ли это слово формальному языку, определяемому этой грамматикой. Для решения этой задачи обычно используются алгоритмы анализа слева направо, которые просматривают в этом направлении символы цепочки.
Например, цепочка [[x]] принадлежит языку L(G2), описанному грамматикой G2.
G2=(T2, N2, P2, A), где
T2 = {х, +, [, ]},
N2 ={А,В},
P2 = {А®х, А®[В], В®А, В®В+А}.
Действительно, заданную цепочку можно получить, применив последовательно по одному из правил вывода, заданному в Р2.
АÞ [В]Þ [А]Þ [[В]]Þ [[А]]Þ [[х]].
Следовательно, цепочка [[х]] принадлежит формальному языку L(G2).
Различают две стратегии: стратегия анализа сверху вниз и снизу вверх. При анализе сверху вниз для построения вывода заданной цепочки начинают с ГЛАВНОГО нетерминального символа и выбирают правила из заданного множества так, чтобы прийти к заданной цепочке w.
В примере [[х]] в грамматике G2 главных нетерминальных символов А среди заданного множества правил вывода для А есть два: А ® х и А®[В]. Первое из них не дает возможности вывести [[х]]. Берем А ® [В], то есть А заменяем на [В]. Теперь нужно выбирать из двух правил вывода для В.
В ® А и В ® В+А.
Выбираем В ® А, заменяем в [В] В на А и получаем [А]. Вновь из двух правил вывода для А выбираем А ® [В]. Заменяем в [А] А на [В]. Получаем [[В]]. Вновь из двух правил для вывода В выбираем В® А и заменяем в [[В]] В на А. Получим [[А]]. И, наконец, из двух правил вывода для А выбираем А®х. Заменяем в [[А]] А на х и получаем требуемую цепочку [[х]]. Таким образом, доказано, что заданная цепочка действительно принадлежит языку, определяемому грамматикой G2.
При анализе сверху вниз основная проблема в определении необходимого правила V ® ai для построения следующего шага вывода цепочки w, когда в найденной части А Þ* nVb известны левый нетерминальный символ V и n правил вывода V ® a1 , V ®a2, …V ® an с левой частью V. Решение этой проблемы, в частности, возможно с помощью алгоритма лексического <А(1) – анализа, который определяет необходимое правило V ® ai в зависимости от первого, еще не распознанного символа х в цепочке w.
Для многих грамматик LA(1) – анализ. Осуществляется LA(1) – анализ путем создания для нетерминалов процедур анализа. Эти процедуры, как правило, оказываются взаимно рекурсивными и часто неэффективными.
Для многих грамматик LA(1) – анализ в таком виде не используется. Тогда приходят к расширенным грамматикам или к синтаксическим диаграммам (графикам).
Синтаксические диаграммы
Это ориентированный граф с двумя фиксированными вершинами: входной, из которой дуги только выходят, и выходной, в которую дуги только входят.

Дуги этого графа могут быть помечены терминальными и нетерминальными символами. В расширенной диаграмме с терминальным Т и нетерминальным N алфавитами каждому нетерминалу А и его правилу вывода А ® a, где a - регулярное выражение в алфавите TUN, отвечает одна синтаксическая диаграмма. При обозначении дуг помеченными терминальными символами условились эти символы писать строчными буквами и заключать в окружность. Нетерминальные символы условились писать заглавными буквами и размещать в прямоугольнике. Регулярное выражение будет обозначаться греческими буквами внутри ромба.
На рисунке 2 показаны примеры изображения дуг, помеченных терминальным символом а, нетерминальным – А и регулярным выражением – a.


Рисунок 2
Алгоритм лексического анализа может быть применен при условиях, что в синтаксических диаграммах нет непомеченных дуг от входной вершины до выходной и в каждом разветвлении ветки начинаются с неодинаковых последующих терминальных символов. По синтаксической диаграмме строится функция анализа выводимых из нетерминала цепочек символов  . Прохождению дуги, помеченной терминальным символом а, отвечает распознавание этого символа (т.е. а) в предъявленном для анализа слове и сдвиг на следующий символ в этом слове (чтение очередного символа из слова).
. Прохождению дуги, помеченной терминальным символом а, отвечает распознавание этого символа (т.е. а) в предъявленном для анализа слове и сдвиг на следующий символ в этом слове (чтение очередного символа из слова).
Прохождению дуги, помеченной нетерминальным символом А, отвечает вызов функции распознавания цепочек, которые выводятся из А. Перед вызовом этой функции предварительно должен быть прочитан первый терминальный символ х, который выводят из А, т.е.  . Функция успешно анализирует цепочку , выводимую из нетерминала А, если в соответствии с синтаксической диаграммой, прочитав посимвольно всю цепочку , удается попасть из входной вершины в выходную.
. Функция успешно анализирует цепочку , выводимую из нетерминала А, если в соответствии с синтаксической диаграммой, прочитав посимвольно всю цепочку , удается попасть из входной вершины в выходную.
Введение в компиляцию
Все изложенные выше сведения о грамматических и формальных языках необходимы для создания трансляторов.
Транслятором называется компьютерная программа, которая осуществляет переход программы на входном языке (например, алгоритмическом) на эквивалентную ей объектную программу. Если входной язык высокого уровня (алгоритмические языки Паскаль, Си и др.), а выходной – машинные коды или АССЕМБЛЕР (т.е. машинно-ориентированный язык), то такой транслятор называется компилятором.
Интерпретатор - разновидность транслятора, который переводит программу на язык простых промежуточных команд и выполняет их.
Препроцессор – транслятор, осуществляющий перевод с одного языка высокого уровня на другой язык тоже высокого уровня.
Итак, транслятор – компьютерная программа, которая читает последовательно символ за символом текст некоторой другой компьютерной программы на каком-то алгоритмическом языке и осуществляет перевод этой программы на другой (выходной) язык. В случае, если транслятором является программа-компилятор, после перевода с алгоритмического языка будет получена компьютерная программа или на ассемблере или в виде последовательности машинных команд в кодах (объектный модуль). Один или нескольких объектных модулей обрабатываются программой - компоновщиком. В результате создается готовая к исполнению программа. Компилятор осуществляет перевод программы на алгоритмическом языке в программу, состоящую из последовательности некоторых промежуточных команд. Сразу же после окончания перевода интерпретатор в отличие от компилятора выполняет полученную программу.
Структура компилятора
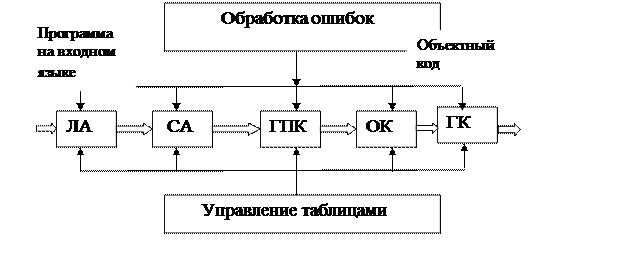
Здесь:
ЛА – лексический анализ;
СА – синтаксический анализ;
ГПК – генерация промежуточного кода;
ОК – оптимизация кода;
ГК – генерация кода.
На всех этапах осуществляется обработка ошибок и происходит заполнение различных таблиц. Рассмотрим более подробно некоторые этапы обработки исходной программы на алгоритмическом языке.
ЛА – лексический анализ. Лексема – это один или несколько символов, имеющих некоторый самостоятельный смысл. В процессе лексического анализа считываемые последовательно из программы на выходном (алгоритмическом) языке символы объединяются в лексемы. Различаются следующие лексемы:
· служебные слова;
· идентификаторы;
· знаки для обозначения операций, а также другие специальные символы;
· числа;
· признак конца считываемого файла.
Служебные (зарезервированные) слова нельзя использовать в программе на алгоритмическом языке в качестве идентификаторов для обозначения переменных и функций. Например, для языка Си это if, do, while, for, return, goto, char, int, float и др. Поэтому программа-транслятор должна “уметь” отличить эти зарезервированные служебные слова. На следующем этапе происходит построение из лексем синтаксических структур, которые могут быть составляющими других. На всех этапах осуществляются обнаружение ошибок в тексте транслируемой программы, а также заполнение таблиц. Конкретно заполняются таблица идентификаторов переменных и функций, таблица объектов, которые обрабатываются (константы, глобальные и локальные переменные), таблица функций (главная функция main и др.), таблица команд.
Проходы компилятора
При реализации компилятора одна или несколько фаз (этапов, а может и часть фазы) объединяются в программные модули. Их называют проходами. За каждый проход считываются файл с программой на алгоритмическом языке, а также результат предыдущего прохода. Во время каждого прохода происходит преобразование, заданное фазами, и записывается результат. Количество проходов определяется особенностями алгоритмического языка и ПЭВМ. Есть одно-, двух- и многопроходные компиляторы. Многопроходной компилятор занимает меньше оперативной памяти ПЭВМ, чем однопроходной, но работает медленно из-за необходимости многоразового чтения и записи файлов. В однопроходном компиляторе ведущей фазой является фаза синтаксического анализа. Она каждый раз, когда ей нужна лексема, запрашивает фазу лексического анализа, управляет генерацией промежуточного кода, заполняет таблицы и т.д.
Алгоритмический язык SPL
Используем основные методы компиляции для реализации однопроходного интерпретатора. Этот интерпретатор, написанный на языке Си, должен прочитать, перевести на язык промежуточных команд и выполнить программу, написанную на алгоритмическом языке SPL. SPL (Simple Programming Language) – простой язык программирования. Это учебный язык высокого уровня, который напоминает Паскаль и Си. Ему присущи все особенности алгоритмических языков высокого уровня, за исключением того, что работает он только с одним типом данных – с целыми числами.
Язык SPL, как и любой алгоритмический язык, являет собой набор символов и правил для ввода интерпретации в ЭВМ.
Символы
· Буквы: 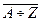 ,
, 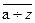 (только латинского алфавита).
(только латинского алфавита).
· Цифры: 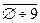 .
.
· Специальные символы: +, -, *, /, %, ( , ) , , ;, =,\n, \t – всего 13 символов.
Идентификаторы
Это имена переменных, констант и функций. Идентификатор – это последовательность букв или букв и цифр, но первой должна быть буква. Количество символов от 1 до 40, символы пробела, перехода на новую строку (\n) и табуляции (\t) в идентификаторе недопустимы.
Константы
Это только целые числа. Описание констант предваряется служебным словом const. Одна константа от другой отделяется запятой. В конце описания должна быть точка с запятой.
Пример: сonst a=12, b=4, d=0;
Переменные
Переменные могут быть только целого типа. Имеются глобальные и локальные переменные. Глобальные переменные могут использоваться всеми функциями, а локальные – только теми функциями, в которых описаны. Описание переменных имеет вид:
int имя_переменной_1, имя_переменной_2.
Пример: int x, y, z, teta.
Выражения
В выражениях применяются знаки +, -, * (умножить), / (деление), % (остаток от деления).
Служебные слова
Напомним, что это зарезервированные слова, которые нельзя использовать в качестве идентификаторов. Это следующие 11 слов: begin, end, read, print, return, if, then, while, do, int, const.
Функции
Как и в языке Си, программа на SPL состоит из одной или нескольких функций. Количество функций и их имена определяет программист, но одна функция должна обязательно называться main, т.к. именно с нее будет начинаться выполнение программы.
Описание программы имеет вид:
Имя_функции (формальные_параметры)
begin
описание локальных констант и переменных;
операторы
end
В отличие от Паскаля после end в конце программы точка не ставится.
Операторы заканчиваются точкой с запятой. Однако перед end точку с запятой ставить нельзя. Оператор условной передачи управления if имеет вид:
if условие then последовательность операторов end
В качестве условия может быть имя переменной или выражение. Если значение переменной или выражения больше нуля, тогда выполняется последовательность операторов между then и end. Иначе переход на следующий за if оператор.
Оператор цикла
while условие do
последовательность операторов
end
Как и для if, “условие” может представлять собой переменную или выражение. Если переменная или результат вычисления больше нуля, тогда вычисляется последовательность операторов между словами do и end. После этого вновь проверяется “условие”. Если результатом проверки условия оказалось число £ 0, то происходит выход из цикла.
При использовании функции в языке SPL результаты их работы можно возвращать или с помощью оператора return или через глобальные переменные, которые описываются в начале программы вне области действия какой-либо из функций. Как и для других языков высокого уровня, в SPL допускаются рекурсии, когда функция может вызывать саму себя.
Ниже приводится пример программы на SPL, в которой, кроме главной функции main( ), также используется функция возведения в степень аb. Назовем ее exp ( ).
exp (а, b)
begin
int z;
z=1;
while b do
if b %2 then
z=z*a
end;
a=a*a;
b=b/2
end;
return z
end
main ( )
begin
int x, y;
read x;
read y;
print exp (x, y)
end
В главной функции описаны и введены с клавиатуры две локальные переменные x, y. Затем в строке print exp (x, y) происходит вызов функции exp (), в которую вместо формальных параметров a и b подаются соответствующие фактические параметры x и y. Функция exp ( ) с помощью оператора return z возвращает в main ( ) результат, который выводится на экран.
Алгоритм возведения ab предлагается рассмотреть самостоятельно, например, вычисляя 27.
Лексический анализ
Сначала составим программу на языке Си, которая предназначена только лишь для распознавания лексем в тексте программы на языке SPL, а также для размещения идентификаторов в специальной таблице TNM. Эта таблица представляет собой глобальный одномерный массив char TNM[400].
В процессе лексического анализа распознаются лексемы:
· служебные слова;
· знаки операций и разделители;
· целые числа;
· идентификаторы;
· признак конца файла.
В программе каждой лексеме ставится в соответствие целое число. Знаки операций и разделители закодированы литеральными константами ‘+’, ‘-‘, ‘*’, ‘/’, ‘%’, ‘=’, ‘(‘, ‘)’, ‘,’, ‘;’. Каждой из них соответствует целое число из таблицы кодов ASCII (М. Уэйт, С. Прата, Д. Мартин. Язык Си.- М.: Изд-во “Мир”, 1988.- 512 с.). В таблице кодов ASCII также закодированы целыми числами символы букв и цифр. Обычно в этой таблице приводятся коды 256 символов.
Для служебных слов имена лексем выбирает программист. Предлагается эти лексемы обозначать соответствующими заглавными буквами с буквой L в конце. Например: служебными словами if и while имена лексем соответственно IFL, WHILEL и т.д. А связь с целыми числами определяется с помощью перечисляемых констант целого типа.
enum {BEGINL=257, ENDL, READL, PRITL, RETRL, IFL, THENL, WHILEL, DOL, INTL, CONSTL, NUMB, IDEN },
где NUMB – лексема для целого числа;
IDEN – лексема для идентификатора.
Благодаря применению enum {}, лексема BEGINL получила числовое значение 257, ENDL – 258 и т.д. Таким образом, при написании программы нет необходимости помнить, что лексема BEGINL закодирована числом 257, а ENDL – 258. Везде, где нужно сослаться на эти лексемы, удобнее писать BEGINL, ENDL и т.д., а вместо них будут представляться числа 257, 258 и т.д.
Кроме перечисленных лексем, также используется признак конца файла EOF. В файле stdio.h есть директива препроцессора #define EOF – 1 . Из нее видно, что EOF закодирован – 1.
Текст программы на Си для лексического анализа программы на SPL приведен ниже. Целесообразно привести некоторые пояснения к этой программе. В ней используются глобальные переменные и приведенные выше в enum {} перечисленные константы:
int lex; //распознанная лексема (целое число);
int lval; // значение лексемы. Для константы – это числовое значение, а для идентификатора – адрес в таблице идентификаторов TNM;
int nst=0; // номер считываемой строки в программе на языке SPL;
char nch=’\n’; // считываемый символ из программы на SPL;
char TNM [400]; // таблица идентификаторов;
char * ptn=TNM; // указатель на первый свободный элемент в таблице идентификаторов. В самом начале он стоит на TNM [0], т.к. имя массива TNM в языке Си является адресом его самого первого (т.е. нулевого) элемента;
FILE * PF; // указатель на файл с текстом программы на SPL;
FILE * padres // указатель на файл, в который будут заноситься адреса идентификаторов в таблице TNM.
В программе лексического анализа при вызове функции main () используются параметры. Заголовок функции main ( ) имеет вид: void main (int av, char * av [ ]). Здесь ac – количество параметров (символьных строк); char* av [ ] – массив показателей. Конкретно, в av [0] автоматически заносятся имя файла с готовой для исполнения программой (например, part1.exe).
В av [1] следует занести самостоятельно имя файла с текстом программы на языке SPL. Например, var2.s Для этого необходимо, находясь в среде Borland C++ , вызвать в главном меню Run/arguments и в появившееся диалоговое окно ввести требуемое имя файла на SPL. В данном примере – это var2.s. Предполагается, что var2.s находится в текущей директории. Чтобы обеспечить обращение к этому файлу при запуске Borland C++ из другой директории, надо ввести полный путь, например, C:\\USER\\SPL\\var2.s part1.s ¿.
Для лучшего понимания работы лексического анализа part1.c предлагается рассмотреть блок-схемы отдельных его функций.
Вначале проверяется количество параметров ac. Должно быть не меньше двух, например, part1.exe в av[0] и var2.s в av [1]. Если параметров меньше двух, происходит остановка работы программы. Иначе открывается файл для чтения с текстом на SPL. В примере это – var2.s и его имя находится в av [1]. Если файл открылся, то происходит вызов функции get ( ), которая является “поставщиком” лексем.
4. 1 Блок-схема функции void main (int ac, char * av [ ])

В функции get () блок №1 в интерпретаторе должен быть if(nch==EOF)
{ lex=EOF;
.-.-.-.-.-.-.-.-
return;
}
Однако программа part1.c предназначена только лишь для того, чтобы прочитать текст программы на SPL, распознать лексемы, а идентификаторы занести в специальную таблицу идентификаторов char TNM [400]. Поэтому в данной программе в функции get ( ) блок №1 являет собой цикл while (nch!=EOF). Он позволяет прочитать весь текст программы на SPL до конца файла. Далее идет цикл while (isspace(nch)), позволяющий пропускать символы пробела, табуляции, перехода на новую строку и на новую страницу.
Если символ nch, прочитанный из файла с помощью функции get (), не является одним из перечисленных выше, то происходит его распознавание с вызовом функции number( ) или word( ).
Если nch является одним из перечисленных специальных символов, например, ‘(’, ‘)’, ‘+’ и т.д., то лексема получает соответствующее значение, считывается новый символ и происходит возврат в цикл (блок №1). В противном случае выдается сообщение о недопустимом символе и происходит выход из программы.
Полный синтаксис языка SPL
Из структурной схемы компилятора видно, что после лексического анализа следует фаза синтаксического анализа. То же самое имеет место и для идентификатора. Для ее реализации нужно знать основные конструкции языка SPL. Эти конструкции обозначаются нетерминальными символами, для каждого из которых имеется правило вывода. Терминальными символами являются лексемы.
Как уже говорилось выше, язык SPL, как и любой другой формальный язык, описывается грамматикой. Конкретно, его полный синтаксис ниже представлен расширенной грамматикой в виде последовательности регулярных выражений. Для каждого нетерминального символа имеется отдельное регулярное выражение. Условимся нетерминальные символы в регулярных выражениях обозначать заглавными буквами, а терминальные (лексемы) – строчными. Помимо символов ‘*’, ‘,’, ‘\’ в регулярных выражениях также будут использованы квадратные скобки ‘[‘, ‘]’ для выделения необязательных цепочек символов.
Void get()
{
while(nch!=EOF)
{
while(isspace(nch))
{
if(nch=='\n')
nst++;
nch=getc(PF);
}
if(isdigit(nch))
number();
else
if(isalpha(nch))
word();
else
if(nch=='('||nch==')'||nch==','||nch==';'||nch=='='||nch=='+'||nch=='-'||nch=='*'||nch=='/'||nch=='%')
{
lex=nch;
nch=getc(PF);
}
}
if(nch==EOF)
lex=EOF;
else
puts("Hедопустимый символ");
return;
}
Void number()
{
for(lval=0;isdigit(nch);nch=getc(PF))
lval=lval*10+nch-'0';
lex=NUMB;
return;
}
void word()
{
static int cdl[]={BEGINL,ENDL,IFL,THENL,WHILEL,DOL,RETRL,READL,
PRITL,INTL,CONSTL,IDEN,NUMB};
static char*serv[]={"begin","end","if","then","while","do","return","read",
"print","int","const"};
int i;
char tx[40];
char*p;
for(p=tx;isdigit(nch)||isalpha(nch);nch=getc(PF))
*(p++)=nch;
*p='\0';
for(i=0;i<11;i++)
if(strcmp(tx,serv[i])==0)
{
lex=cdl[i];
return;
}
lex=IDEN;
lval=(int)add(tx);
printf("Адрес для %s =%p\n",tx,lval);
fprintf(padres,"Адрес для %s =%p\n",tx,lval);
return;
}
char TNM[400];
char*ptn=TNM;
char*add(char*nm)
{
char*p;
for(p=TNM;p<ptn;p+=strlen(p)+1)
if(strcmp(p,nm)==0)
return p;
if((ptn+=strlen(nm)+1)>TNM+400)
{
puts("Переполнение таблицы");
exit(0);
}
return(strcpy(p,nm));
}
И т. д.
Пример выполнения курсовой работы
Вариант задания курсовой работы
Составить программу на Си для лексического анализа программы на модифицированном языке SPL,в котором все ключевые слова переведены на русский язык и вместо begin и end используются соответственно левая и правая фигурные скобки. Вывести в файл и на экран таблицу идентификаторов и их адресов.
Вариант программы на модифицированном языке SPL (вычисляет xy), где по условию задачи все ключевые слова заменены на соответствующие на русском языке, а вместо begin и end используются соответственно { и }
exp(a,b)
{
целый z;
z=1;
пока b делать
если b%2 тогда z=z*a };
a=a*a;b=b/2
};
возврат z
}
main()
{
целый x,y;
читать x;
читать y;
печатать exp(x,y) }
Замечание: жирным шрифтом выделены изменения, которые необходимо внести в предыдущую программу, согласно варианту задания.
#include<stdio.h>
#include<stdlib.h>
#include<ctype.h>
#include<conio.h>
#include<alloc.h>
#include<string.h>
/*Коды лексем языка SPL*/
enum{BEGINL=257,ENDL,IFL,THENL,WHILEL,DOL,RETRL,READL,PRITL,INTL,CONSTL,IDEN,NUMB};
int nst=0;
int lval,lex;
static char nch='\n';
FILE*PF,*padres;
void get(void);
void number(void);
void word(void);
char*add(char*nm);
int isalpharus(char c);
int isspace1(char c);
int isdigit1(char c);
void main(int ac,char*av[])
{
clrscr();
if(!ac)
puts("Hет исходного файла");
PF=fopen(av[1],"r");
padres=fopen("getrez.dan","w");
if(!PF)
puts("Файл не открывается");
else
get();
}
Void get()
{
while(nch!=EOF)
{
while(isspace1(nch))
{
if(nch=='\n')
nst++;
nch=getc(PF);
}
if(isdigit1(nch))
number();
else
if(isalpharus(nch))
word();
else
if(nch=='('||nch==')'||nch==','||nch==';'||nch=='='||nch=='+'||nch=='-'||nch=='*'||nch=='/'||nch=='%'||nch=='{'||nch=='}')
{
lex=nch;
nch=getc(PF);
}
}
if(nch==EOF)
lex=EOF;
else
puts("Hедопустимый символ");
return;
}
Void number()
{
for(lval=0;isdigit1(nch);nch=getc(PF))
lval=lval*10+nch-'0';
lex=NUMB;
return;
}
void word()
{
static int cdl[]={BEGINL,ENDL,IFL,THENL,WHILEL,DOL,RETRL,READL,
PRITL,INTL,CONSTL,IDEN,NUMB};
static char*serv[]={"{","}","если","тогда","пока","делать","возврат","читать","печатать","целый","const"};
int i;
char tx[40];
char*p,*add();
for(p=tx;isdigit1(nch)||isalpharus(nch);nch=getc(PF))
*(p++)=nch;
*p='\0';
for(i=0;i<11;i++)
if(strcmp(tx,serv[i])==0)
{
lex=cdl[i];
return;
}
lex=IDEN;
lval=(int)add(tx);
printf("Адрес для %s =%p\n",tx,lval);
fprintf(padres,"Адрес для %s =%p\n",tx,lval);
return;
}
char TNM[400];
char*ptn=TNM;
char*add(char*nm)
{
char*p,*strcpy();
for(p=TNM;p<ptn;p+=strlen(p)+1)
if(strcmp(p,nm)==0)
return p;
if((ptn+=strlen(nm)+1)>TNM+400)
{
puts("Переполнение таблицы");
exit(0);
}
return(strcpy(p,nm));
}
/* Добавляем к исходной программе функции пользователя для распознавания букв, специальных знаков и цифр */
int isalpharus(char c)
{
int v;
if(isalpha(c)||c=='а'||c=='б'||c=='в'||c=='г'||c=='д'||c=='е'
||c=='ж'||c=='з'||c=='д'||c=='е'||c=='ж'||c=='з'||c=='и'|| c=='й'||c=='к'||c=='л'||c=='м'||c=='н'||c=='о'||c=='п'|| c=='р'||c=='с'||c=='т'||c=='у'||c=='ф'||c=='х'||c=='ц'||c=='ч'||c=='ш'||c=='щ'||c=='ы'||c=='э'||c=='ю'||c=='я'||c== 'ь')
v=8;
Else
v=0;
return v;
}
int isspace1(char c)
{
int v;
if(c=='\ '||c=='\n'||c=='\t'||c=='\f')
v=1;
Else
v=0;
return v;
}
int isdigit1(char c)
{
int v;
if(c=='0'||c=='1'||c=='2'||c=='3'||c=='4'||c=='5'||c=='6'||c=='7'||c=='8'||c=='9')
v=2;
Else
v=0;
return v;
}
Варианты заданий для курсовой работы
Вариант 1
Составить программу на Си для лексического и синтаксического анализов программы на модифицированном языке SPL,в котором все ключевые слова переведены на русский язык и вместо begin и end используются соответственно левая и правая фигурные скобки. Вывести в файл и на экран таблицу идентификаторов и их адресов.
Вариант 2
Составить программу на Си для лексического и синтаксического анализов программы на модифицированном языке SPL,в котором все ключевые слова переведены на украинский язык и вместо begin и end используются соответственно левая и правая фигурные скобки. Вывести в файл и на экран таблицу идентификаторов и их адресов.
Вариант 3
Составить программу на Си для лексического и синтаксического анализов программы на модифицированном языке SPL, в котором все ключевые слова переведены на русский язык и вместо begin и end используются слова start и finish. Вывести в файл и на экран таблицу идентификаторов и их адресов.
Вариант 4
Составить программу на СИ для лексического и синтаксического анализов программы на модифицированном языке SPL, в котором ключевые слова переведены на украинский язык и вместо begin и end bиспользуются слова start и finish. Вывести в файл и на экран таблицу идентификаторов и их адресов.
Вариант 5
Составить программу на Си для лексического и синтаксического анализов программы на модифицированном языке SPL, в котором все ключевые слова переведены на русский язык, а вместо Int используется Var. Вывести в файл и на экран таблицу идентификаторов и их адресов.
Вариант 6
Составить программу на СИ для лексического и синтаксического анализов программы на модифицированном языке SPL, в котором ключевые слова переведены на украинский язык и вместо слова NUMB используется DIGIT. Вывести в файл и на экран таб
Последнее изменение этой страницы: 2016-07-22
lectmania.ru. Все права принадлежат авторам данных материалов. В случае нарушения авторского права напишите нам сюда...