Категории:
ДомЗдоровьеЗоологияИнформатикаИскусствоИскусствоКомпьютерыКулинарияМаркетингМатематикаМедицинаМенеджментОбразованиеПедагогикаПитомцыПрограммированиеПроизводствоПромышленностьПсихологияРазноеРелигияСоциологияСпортСтатистикаТранспортФизикаФилософияФинансыХимияХоббиЭкологияЭкономикаЭлектроника
Сущность задачи проверки статистических гипотез
Статистическая гипотеза представляет собой некоторое предположение о законе распределения случайной величины или о параметрах этого закона, формулируемое на основе выборки [3, 5, 11]. Примерами статистических гипотез являются предположения: генеральная совокупность распределена по экспоненциальному закону; математические ожидания двух экспоненциально распределенных выборок равны друг другу. В первой из них высказано предположение о виде закона распределения, а во второй – о параметрах двух распределений. Гипотезы, в основе которых нет никаких допущений о конкретном виде закона распределения, называют непараметрическими, в противном случае – параметрическими.
Гипотезу, утверждающую, что различие между сравниваемыми характеристиками отсутствует, а наблюдаемые отклонения объясняются лишь случайными колебаниями в выборках, на основании которых производится сравнение, называют нулевой (основной) гипотезой и обозначают Н0. Наряду с основной гипотезой рассматривают и альтернативную (конкурирующую, противоречащую) ей гипотезу Н1. И если нулевая гипотеза будет отвергнута, то будет иметь место альтернативная гипотеза.
Различают простые и сложные гипотезы. Гипотезуназывают простой, если она однозначно характеризует параметр распределения случайной величины. Например, если l является параметром экспоненциального распределения, то гипотеза Н0 о равенстве l =10–простая гипотеза. Сложной называют гипотезу, которая состоит из конечного или бесконечного множества простых гипотез. Сложная гипотеза Н0 о неравенстве l >10 состоит из бесконечного множества простых гипотез Н0 о равенстве l =bi , где bi – любое число, большее 10. Гипотеза Н0 о том, что математическое ожидание нормального распределения равно двум при неизвестной дисперсии, тоже является сложной. Сложной гипотезой будет предположение о распределении случайной величины Х по нормальному закону, если не фиксируются конкретные значения математического ожидания и дисперсии.
Проверка гипотезы основывается на вычислении некоторой случайной величины – критерия, точное или приближенное распределение которого известно. Обозначим эту величину через z, ее значение является функцией от элементов выборки z=z(x1, x2, …, xn). Процедура проверки гипотезы предписывает каждому значению критерия одно из двух решений – принять или отвергнуть гипотезу. Тем самым все выборочное пространство и соответственно множество значений критерия делятся на два непересекающихся подмножества S0 и S1. Если значение критерия z попадает в область S0, то гипотеза принимается, а если в область S1, – гипотеза отклоняется. Множество S0называется областью принятия гипотезы или областью допустимых значений, а множество S1 – областью отклонения гипотезы или критической областью. Выбор одной области однозначно определяет и другую область.
Принятие или отклонение гипотезы Н0 по случайной выборке соответствует истине с некоторой вероятностью и, соответственно, возможны два рода ошибок. Ошибка первого рода возникает с вероятностьюa тогда, когда отвергается верная гипотеза Н0 и принимается конкурирующая гипотеза Н1. Ошибка второго рода возникает с вероятностью b в том случае, когда принимается неверная гипотеза Н0, в то время как справедлива конкурирующая гипотеза Н1. Доверительная вероятность – это вероятность не совершить ошибку первого рода и принять верную гипотезу Н0. Вероятность отвергнуть ложную гипотезу Н0называется мощностью критерия. Следовательно, при проверке гипотезы возможны четыре варианта исходов
| Гипотеза Н0 | Решение | Вероятность | Примечание |
| Верна | Принимается | 1–a | Доверительная вероятность |
| Отвергается | a | Вероятность ошибки первого рода | |
| Неверна | Принимается | b | Вероятность ошибки второго рода |
| Отвергается | 1–b | Мощность критерия |
Потери и риск
Последствия от принятия решений следует оценивать по степени их соответствия поставленной цели. Это соответствие, в принципе, может быть определено с помощью количественной меры, определяющей выигрыш или потери от принятия решения. Эта мера называется функцией потерь (штрафа) или функцией выигрыша (целевой функцией). Для определенности будем использовать функцию потерь, которую, естественно, следуетминимизировать, чтобы решение было оптимальным.
Потери могут зависеть не только от принятого решения  , но и от реальной ситуации, описываемой параметрами
, но и от реальной ситуации, описываемой параметрами 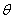 . Возможно, что потери зависят и от наблюдений
. Возможно, что потери зависят и от наблюдений  . В общем случае функция потерь имеет вид
. В общем случае функция потерь имеет вид 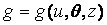 . В частных случаях может быть
. В частных случаях может быть  ,
,  и т. д.
и т. д.
Если бы значение было известно, т. е. полностью определена реальная ситуация 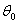 , то при получении наблюдения
, то при получении наблюдения  оптимальным решением была бы точка минимума
оптимальным решением была бы точка минимума  функции
функции 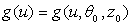 , т. е.оптимальным решающим правилом была бы просто минимизация известной функции по
, т. е.оптимальным решающим правилом была бы просто минимизация известной функции по 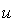 при заданных значениях ее параметров
при заданных значениях ее параметров  и
и  . Полученное таким образом решение является каждый раз наилучшим.
. Полученное таким образом решение является каждый раз наилучшим.
В реальности же являются скрытыми параметрами, т. е. действительная обстановка может быть, в лучшем случае, известна только приближенно. В таком случае уже невозможно каждый раз находить наилучшее решение – неизбежны просчеты из-за ошибочной оценки ситуации.
Единственное, что можно сделать в сложившемся положении, это попытаться найти такое решающее правило, при котором минимальными будут средние потери, т. е. среднее значение функции потерь, называемое риском.Правило, минимизирующее риск, будем называть оптимальным.
Для нахождения среднего значения функции потерь 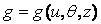 нужно задать распределение вероятностей на пространстве ее аргументов
нужно задать распределение вероятностей на пространстве ее аргументов  , что может быть сделано следующим образом.
, что может быть сделано следующим образом.
Закон распределения вероятностей возможных ситуаций описывается ПРВ 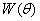 на
на  .
.
Наблюдения z должны быть в той или иной мере связаны с 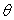 , иначе в них нет никакой надобности. Эта связь может быть описана условной ПРВ
, иначе в них нет никакой надобности. Эта связь может быть описана условной ПРВ  на пространстве наблюдений
на пространстве наблюдений  , которая называется функцией правдоподобия (ФП).
, которая называется функцией правдоподобия (ФП).
Решения u принимаются в зависимости от z, это и есть решающее правило. В наиболее общем случае это правило рандомизировано и определяется условной вероятностной мерой, для определенности заданной условной ПРВ  .
.
Таким образом, совместная ПРВ параметров  ,
, 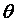 ,
, 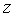 есть функция
есть функция  , определенная на пространстве
, определенная на пространстве  .
.
В зависимости от степени усреднения можно рассматривать различные типы рисков. Средний риск. Если известно распределение 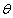 и
и  (заданы ПРВ и
(заданы ПРВ и 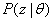 ), то для любого решающего правила
), то для любого решающего правила 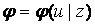 можно найти безусловное математическое ожидание функции потерь, зависящее только от этого правила и называемое средним риском:
можно найти безусловное математическое ожидание функции потерь, зависящее только от этого правила и называемое средним риском:
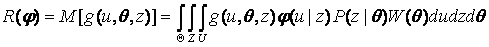 . (2.1)
. (2.1)
Оптимизация принятия решений заключается в выборе такого правила (т. е. ПРВ 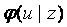 ), при котором средний риск (2.1) минимален.
), при котором средний риск (2.1) минимален.
Для нерандомизированых правил  распределение
распределение 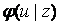 сосредоточено в точке
сосредоточено в точке 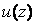 , т. е.
, т. е.
 (2.2)
(2.2)
где 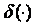 – функция Дирака, и (2.1) принимает вид
– функция Дирака, и (2.1) принимает вид
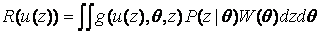 . (2.3)
. (2.3)
Здесь и в дальнейшем, если не возникает недоразумений, будем опускать обозначения областей интегрирования. Выражение (2.3) определяет средний риск для любого правила  , а оптимизация принятия решений заключается в выборе такого правила
, а оптимизация принятия решений заключается в выборе такого правила  , при котором риск (2.3) минимален.
, при котором риск (2.3) минимален.
Априорным риском называется величина
 , (2.4)
, (2.4)
где не зависит от . Если, кроме того, 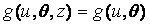 , то
, то
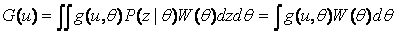 . (2.5)
. (2.5)
Выражения (2.4) и (2.5) определяют априорную оценку потерь, связанных с решением , принимаемым при отсутствии наблюдений или при их игнорировании. Такое решение может быть спланировано заранее, еще до наступления момента, когда решение необходимо принимать. В такой постановке оптимальным решением является 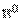 , минимизирующее (2.4) или (2.5), оно учитывает только априорную информацию.
, минимизирующее (2.4) или (2.5), оно учитывает только априорную информацию.
Апостериорным риском называется условное математическое ожидание функции потерь для данного решения  при данном значении
при данном значении  . Для этого найдем по формуле Байеса апостериорное условное распределение
. Для этого найдем по формуле Байеса апостериорное условное распределение 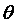 при заданном значении :
при заданном значении :
 . (2.6)
. (2.6)
Апостериорный риск определится усреднением функции потерь по ПРВ (2.6):
 . (2.7)
. (2.7)
Последнее изменение этой страницы: 2016-08-11
lectmania.ru. Все права принадлежат авторам данных материалов. В случае нарушения авторского права напишите нам сюда...